Lesson 1: Review
In this lesson we will refresh a few essential concepts which will be required for the remainder of the course.
One can view a unit as the smallest testable part of an application. In procedural programming, a unit could be an entire module, but it is more commonly an individual function or procedure. In object-oriented programming, a unit is often an entire interface, such as a class, but could be an individual method. Unit tests are short code fragments created by programmers during the development process. It forms the basis for component testing.
Using an automation framework, the developer codes criteria, or result that is known to be good, into the test to verify the unit's correctness. During test case execution, the framework logs tests that fail any criterion. Many frameworks will also automatically flag these failed test cases and report them in a summary. Depending upon the severity of a failure, the framework may halt subsequent testing.
As a consequence, unit testing is traditionally a motivator for programmers to create decoupled and cohesive code bodies. This practice promotes healthy habits in software development. Design patterns, unit testing, and refactoring often work together so that the best solution may emerge.
Advantages
The goal of unit testing is to isolate each part of the program and show that the individual parts are correct. A unit test provides a strict, written contract that the piece of code must satisfy. As a result, it affords several benefits.
Find problems early
Unit testing finds problems early in the development cycle. This includes both bugs in the programmer's implementation and flaws or missing parts of the specification for the unit. The process of writing a thorough set of tests forces the author to think through inputs, outputs, and error conditions, and thus more crisply define the unit's desired behaviour. The cost of finding a bug before coding begins or when the code is first written is considerably lower than the cost of detecting, identifying, and correcting the bug later; bugs may also cause problems for the end-users of the software.
In test-driven development (TDD), which is frequently used in both extreme programming and scrum, unit tests are created before the code itself is written. When the tests pass, that code is considered complete. The same unit tests are run against that function frequently as the larger code base is developed either as the code is changed or via an automated process with the build. If the unit tests fail, it is considered to be a bug either in the changed code or the tests themselves. The unit tests then allow the location of the fault or failure to be easily traced. Since the unit tests alert the development team of the problem before handing the code off to testers or clients, it is still early in the development process.
Facilitates change
Unit testing allows the programmer to refactor code or upgrade system libraries at a later date, and make sure the module still works correctly (e.g., in regression testing). The procedure is to write test cases for all functions and methods so that whenever a change causes a fault, it can be quickly identified. Unit tests detect changes which may break a design contract.
Simplifies integration
Unit testing may reduce uncertainty in the units themselves and can be used in a bottom-up testing style approach. By testing the parts of a program first and then testing the sum of its parts, integration testing becomes much easier.
Documentation
Unit testing provides a sort of living documentation of the system. Developers looking to learn what functionality is provided by a unit, and how to use it, can look at the unit tests to gain a basic understanding of the unit's interface (API).
Unit test cases embody characteristics that are critical to the success of the unit. These characteristics can indicate appropriate/inappropriate use of a unit as well as negative behaviours that are to be trapped by the unit. A unit test case, in and of itself, documents these critical characteristics, although many software development environments do not rely solely upon code to document the product in development.
Design
When software is developed using a test-driven approach, the combination of writing the unit test to specify the interface plus the refactoring activities performed after the test is passing, may take the place of formal design. Each unit test can be seen as a design element specifying classes, methods, and observable behaviour.
Disadvantages
As with all programming techniques and patterns, unit tests have disadvantages associated with them. These however should not be used as an excuse to avoid unit testing.
Decision problem
Testing will not catch every error in the program, because it cannot evaluate every execution path in any but the most trivial programs. This problem is a superset of the halting problem, which is undecidable. The same is true for unit testing. Additionally, unit testing by definition only tests the functionality of the units themselves. Therefore, it will not catch integration errors or broader system-level errors (such as functions performed across multiple units, or non-functional test areas such as performance).
Not integration testing
An elaborate hierarchy of unit tests does not equal integration testing. Integration with peripheral units should be included in integration tests, but not in unit tests. Integration testing typically still relies heavily on humans testing manually; high-level or global-scope testing can be difficult to automate, such that manual testing often appears faster and cheaper.
Combinatorial problem
Software testing is a combinatorial problem. For example, every Boolean decision statement requires at least two tests: one with an outcome of "true" and one with an outcome of "false". As a result, for every line of code written, programmers often need 3 to 5 lines of test code. This obviously takes time and its investment may not be worth the effort. There are also many problems that cannot easily be tested at all – for example those that are nondeterministic or involve multiple threads. In addition, code for a unit test is likely to be at least as buggy as the code it is testing.
Realism
Another challenge related to writing the unit tests is the difficulty of setting up realistic and useful tests. It is necessary to create relevant initial conditions so the part of the application being tested behaves like part of the complete system. If these initial conditions are not set correctly, the test will not be exercising the code in a realistic context, which diminishes the value and accuracy of unit test results.
Record keeping
To obtain the intended benefits from unit testing, rigorous discipline is needed throughout the software development process. It is essential to keep careful records not only of the tests that have been performed, but also of all changes that have been made to the source code of this or any other unit in the software. Use of a version control system is essential. If a later version of the unit fails a particular test that it had previously passed, the version-control software can provide a list of the source code changes (if any) that have been applied to the unit since that time.
Sustainability challenges
It is also essential to implement a sustainable process for ensuring that test case failures are reviewed daily and addressed immediately. If such a process is not implemented and ingrained into the team's workflow, the application will evolve out of sync with the unit test suite, increasing false positives and reducing the effectiveness of the test suite.
Platform differences
Unit testing embedded system software presents a unique challenge: Because the software is being developed on a different platform than the one it will eventually run on, you cannot readily run a test program in the actual deployment environment, as is possible with desktop programs.
Frameworks
There are plenty of unit testing frameworks for C++. The following are a few popular ones:
Catch is one of the most popular frameworks, and will be used in this course.
References
https://web.stanford.edu/~ouster/cgi-bin/cs190-spring15/lecture.php?topic=testing
http://dbmanagement.info/Books/MIX/Best_Practices_in_Unit_Testing_Automation.pdf
As a strongly-typed language, C++ requires all variables to have a specific type, either explicitly declared by the programmer or deduced by the compiler. However, many data structures and algorithms look the same no matter what type they are operating on. Templates enable you to define the operations of a class or function, and let the user specify what concrete types those operations should work on.
Defining Templates
A template is a construct that generates an ordinary type or function at compile time based on arguments the user supplies for the template parameters.
template <typename T>
T minimum( const T& lhs, const T& rhs )
{
return lhs < rhs ? lhs : rhs;
}
T is a template parameter; the typename (or class) keyword says that this parameter is a placeholder for a type. When the function is called, the compiler will replace every instance of T with the concrete type argument that is either specified by the user or deduced by the compiler. The process in which the compiler generates a class or function from a template is referred to as template instantiation; minimum<int>; is an instantiation of the template minimum<T>.const int a = 1234;
const int b = 2341;
const int i = minimum<int>( a, b );
// or more concisely since the compiler can deduce the type of T from the arguments a and b
const int j = minimum(a, b);
Type parameters
In the minimum template above, note that the type parameter T is not qualified in any way until it is used in the function call parameters, where the const and reference qualifiers are added.
There is no practical limit to the number of type parameters. Separate multiple parameters by commas:
template <typename T, typename U, typename V> class Foo{};
class is equivalent to typename in this context. You can express the previous example as:template <class T, class U, class V> class Foo{};
template<typename... Arguments> class vtclass;
vtclass<> vtinstance1;
vtclass<int> vtinstance2;
vtclass<float, bool> vtinstance3;
std::vector in the Standard Library to store ints, doubles, strings, MyClass, const MyClass*, MyClass&. The primary restriction when using templates is that a type argument must support any operations that are applied to the type parameters. For example, if we call minimum using MyClass as in this example:struct MyClass
{
int num;
std::string description;
};
int main()
{
const MyClass mc1{1, "hello"};
const MyClass mc2{2, "goodbye"};
auto result = minimum( mc1, mc2 ); // Error!
}
MyClass does not provide an overload for the < operator.There is no inherent requirement that the type arguments for any particular template all belong to the same object hierarchy, although you can define a template that enforces such a restriction. You can combine object-oriented techniques with templates; for example, you can store a
Derived* in a std::vector. Note that the arguments must be pointers.std::vector<MyClass*> vec;
MyDerived d{3, "back again", time(0)};
vec.push_back(&d);
// or more realistically:
std::vector<shared_ptr<MyClass>> vec2;
vec2.emplace_back(std::make_shared<MyDerived>());
std::vector and other standard library containers impose on elements of T is that T be copy-assignable and copy-constructible.Non-type parameters
Unlike generic types in other languages such as C# and Java, C++ templates support non-type parameters, also called value parameters. For example, you can provide a constant integral value to specify the length of an array, as with this example that is similar to the std::array class in the Standard Library:
template<typename T, std::size_t L>
class MyArray
{
T arr[L];
public:
MyArray() { ... }
};
std::size_t value is passed in as a template argument at compile time and must be constant.Other kinds of values including pointers and references can be passed in as non-type parameters. For example, you can pass in a pointer to a function or function object to customise some operation inside the template code.
Templates as template parameters
A template can be a template parameter. In this example,
MyClass2 has two template parameters: a typename parameter T and a template parameter Arr:template<typename T, template<typename U, int I> class Arr>
class MyClass2
{
T t; //OK
Arr<T, 10> a;
U u; //Error. U not in scope
};
Arr parameter itself has no body, its parameter names are not needed. In fact, it is an error to refer to Arr's typename or class parameter names from within the body of MyClass2. Arr's type parameter names can be omitted, as shown in this example:template<typename T, template<typename, int> class Arr>
class MyClass2
{
T t; //OK
Arr<T, 10> a;
};
Default template arguments
Class and function templates can have default arguments. When a template has a default argument you can leave it unspecified when you use it. For example, the std::vector template has a default argument for the allocator:
template <class T, class Allocator = allocator<T>> class vector;
In most cases the default std::allocator class is acceptable, so you use a vector like so:
vector<int> myInts;
But if necessary you can specify a custom allocator
vector<int, MyAllocator> ints;
For multiple template arguments, all arguments after the first default argument must have default arguments.
When using a template whose parameters are all defaulted, use empty angle brackets:
template<typename A = int, typename B = double>
class Bar
{
//...
};
...
int main()
{
Bar<> bar; // use all default type arguments
}
Template specialisation
In some cases, it is not possible or desirable for a template to define exactly the same code for any type. For example, you might wish to define a code path to be executed only if the type argument is a
pointer, or a std::wstring, or a type derived from a particular base class. In such cases you can define a specialisation of the template for that particular type. When a user instantiates the template with that type, the compiler uses the specialisation to generate the class, and for all other types, the compiler chooses the more general template. Specialisations in which all parameters are specialised are complete specialisations. If only some of the parameters are specialised, it is called a partial specialisation.template <typename K, typename V>
class MyMap{/*...*/};
// partial specialisation for string keys
template<typename V>
class MyMap<std::string, V> {/*...*/};
...
MyMap<int, MyClass> classes; // uses original template
MyMap<std::string, MyClass> classes2; // uses the partial specialisation
Usually when writing code it is easiest to precede from concrete to abstract; therefore, it is easier to write a class for a specific datatype and then proceed to a templated generic class.
Compile Time Polymorphism
Templates support compile-time polymorphism, also termed implicit interface. Unlike runtime polymorphism that requires inheritance and virtual functions, compile time polymorphism using templates only require that a valid template specialisation can be generated by the compiler for input types.
Advantages
- Compile-time interfaces are much more granular than run-time ones. You can use only the requirements of a single function, or a set of functions, as you call them. You don't have to always do the whole interface. The requirements are only and exactly what you need.
- Implicit interfaces are much easier to compose and multiply "inherit" than run-time interfaces, and don't impose any kind of binary restrictions - for example, POD classes can use implicit interfaces. There is no need for virtual inheritance or other heavyweight techniques with implicit interfaces.
- The compiler can do way more optimisations for compile-time interfaces. In addition, the extra type safety makes for safer code.
- It is impossible to do value typing for run-time interfaces, because you do not know the size or alignment of the final object. This means that any case which needs/benefits from value typing gains big benefits from templates.
- Generally produces faster code than runtime inheritance.
- Run-time inheritance is way less flexible (due to tight binding of code)
Disadvantages
- Templates are difficult to compile and use, and they can be challenging (at times) porting between compilers. Heavy use of templates can lead to very large compilation times, and requirement for huge amount of free memory.
- Templates cannot be loaded at run-time (obviously), so they have limits in expressing dynamic data structures, for example.
- Run-time inheritance can express some data structures far more easily since the final type is only decided at runtime. Also you can export run-time polymorphic types across C boundaries.
References
https://msdn.microsoft.com/en-us/library/y097fkab.aspx
http://www.cprogramming.com/tutorial/templates.html
The most obvious form of iterator is a pointer: A pointer can point to elements in an array, and can iterate through them using the increment operator (++). But other kinds of iterators are possible. For example, each container type (such as a list) has a specific iterator type designed to iterate through its elements.
Categories
Iterators are classified into five categories depending on the features they implement:

Input and output iterators are the most limited types of iterators: they can perform sequential single-pass input or output operations.
Forward iterators have all the features of input iterators and (if they are not constant iterators) also the features of output iterators, although they are limited to one direction in which to iterate through a range (forward). All standard containers support at least forward iterator types.
Bidirectional iterators are like forward iterators but can also be iterated through backwards.
Random-access iterators implement all the features of bidirectional iterators, and also have the ability to access ranges non-sequentially: distant elements can be accessed directly by applying an offset value to an iterator without iterating through all the elements in between. These iterators have a similar feature to standard pointers (pointers are iterators of this category).
The properties of each iterator category are:
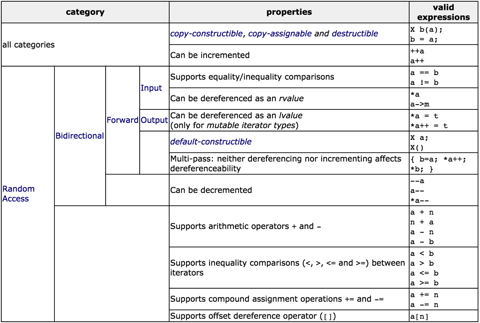
Where X is an iterator type, a and b are objects of this iterator type, t is an object of the type pointed by the iterator type, and n is an integer value.
Rationale
There are two rules for making container-based code general and efficient:
- Never pass containers into a function. Pass iterators instead.
- Never return containers. Return -- or pass -- iterators instead.
Generality
Suppose we wanted to define product() to multiply together the numbers in a container.
We can immediately reject any definition like this:
double product( vector<double> v ) ...
because it is * not general; it only works for vectors *inefficient; it copies the container
But we could define it like this:
template <typename Container>
double product( const Container& container )
{
Container::iterator i = container.begin();
double prod = 1;
while ( i != container.end() ) prod *= *i++;
return prod;
}
This definition seems general. It works for any STL container, e.g.,
vector<double> nums;
...
return product( nums );
Unfortunately, it will not work with regular arrays, e.g.,
double nums[] = { 1.2, 3.0, 3.5, 2.8 };
return product( nums );
since there are no begin() or end() funtions for regular C-style arrays. Furthermore, it does not let us calculate the product of a subrange of the container.
The following definition is clearly more general:
template <typename Iter>
double product( Iter start, Iter stop )
{
double prod = 1;
while ( start != stop ) prod *= *start++;
return prod;
}
This works fine with regular arrays:
double nums[] = { 1.2, 3.0, 3.5, 2.8 };
return product( nums, nums + 4 );
as well as with STL containers and subranges.
Recommendation
Prefer the pre-fix form for incrementing/decrementing (or just use std::advance) the iterator. This in general (as for regular loop counter variables) is more efficient since the compiler does not need to return an unnecessary instance of the previous value of the iterator.