Lesson 8 - Graphs
Graphs are more general purpose data structures than trees. Trees start with a root node, and might connect to other nodes, which means that they could contain subtrees within them. Trees are defined by a certain set of rules: one root node may or may not connect to others, but ultimately, it all stems from one specific place. Some trees have even more specific rules, like binary search trees, which can only ever have two links to two nodes at any given time.
A tree can only flow in one direction, from the root node to either leaf nodes or child nodes. A tree can also only have one-way connections — a child node can only have one parent, and a tree cannot have any loops, or cyclical links.
Discussion
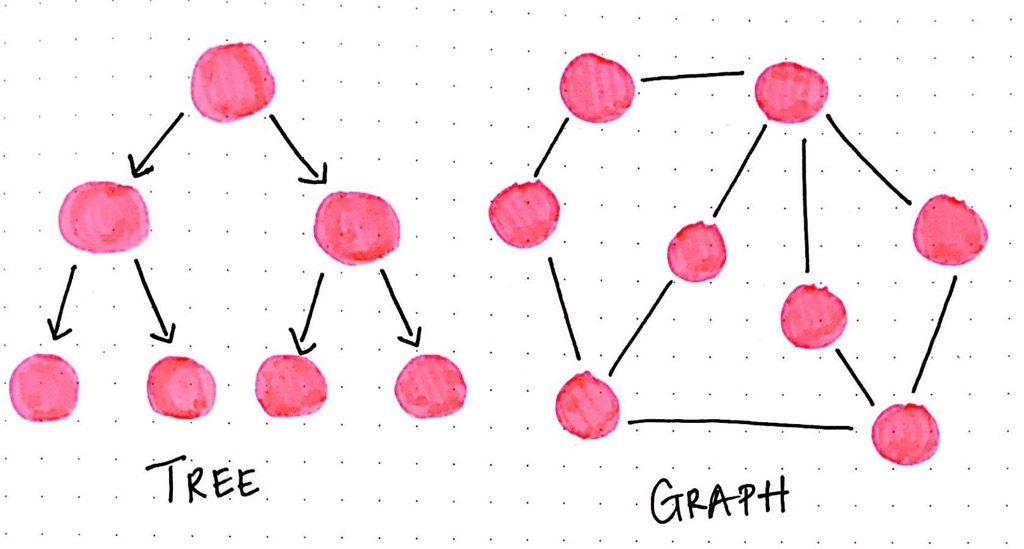
Graphs do not have a concept of a “root” node. Nodes can be connected in any way possible. One node might be connected to five others! Graphs also do not have any notion of “one-directional” flow — instead, they might have direction, or they might have no direction whatsoever. Or, to complicate matters further, they could have some links that have direction and others that don’t!
Every graph always needs to have, at the very least, one single node. Just as how trees need at least one root node in order to be considered a “tree”, similarly, a graph needs at least a single node in order to be considered a “graph”. A graph with just one node is usually referred to as a singleton graph.
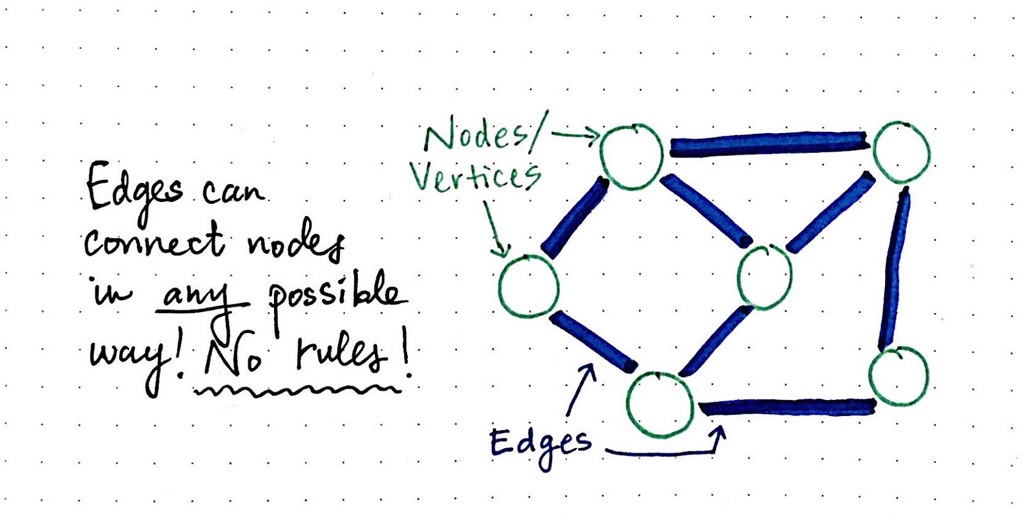
There are no real rules in the way that one node is connected to another node in a graph. Edges (sometimes referred to as links) can connect nodes in any way possible.
Every graph always needs to have, at the very least, one single node. Just as how trees need at least one root node in order to be considered a “tree”, similarly, a graph needs at least a single node in order to be considered a “graph”. A graph with just one node is usually referred to as a singleton graph.
There are no real rules in the way that one node is connected to another node in a graph. Edges (sometimes referred to as links) can connect nodes in any way possible.
Types of Graphs
The different types of edges are important when it comes to recognising and defining graphs. In fact, that’s one of the biggest and most obvious differentiators between one graph and another: the types of edges that it has. For the most part, graphs can have two types of edges: a edge that has a direction or flow, and an edge that has no direction or flow. We refer to these as directed and undirected edges.
In a directed edge, two nodes are connected in a very specific way. In the example below, node A connects to node B; there is only one way to travel between these two nodes — only one direction that we can go. It’s pretty common to refer to the node that we’re starting from as the origin, and the node that we’re traveling to as the destination. In a directed edge, we can only travel from the origin to the destination, and never the other way around.
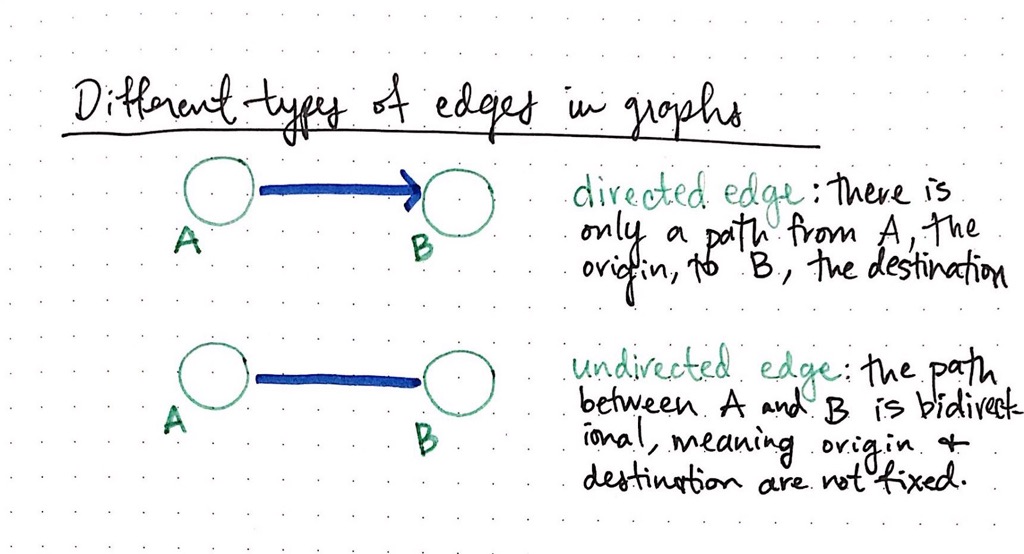
In an undirected edge, the path that we can travel goes both ways. That is to say, the path between the two nodes is bidirectional, meaning that the origin and destination nodes are not fixed.
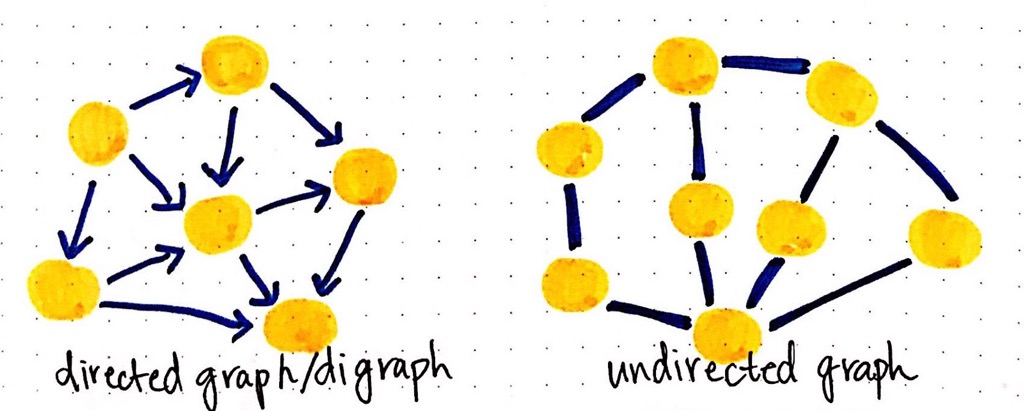
This differentiation is important, because the edges in a graph determine what the graph is called. If all of the edges in a graph are directed, the graph is said to be a directed graph, also called digraph. If all of the edges in a graph are undirected, the graph is said to be an undirected graph!
This differentiation is important, because the edges in a graph determine what the graph is called. If all of the edges in a graph are directed, the graph is said to be a directed graph, also called digraph. If all of the edges in a graph are undirected, the graph is said to be an undirected graph!
Origin
In mathematics, graphs are a way to formally represent a network, which is basically just a collection of objects that are all interconnected.
Computer scientists applied graph theory to code and ultimately implemented graphs as data structures. A lot of the terms that we use to describe and implement graphs are the exact terms that we will find in mathematical references to graph theory.
For example, in mathematical terms, we describe graphs as ordered pairs. This is similar to algebra, where x, y pair coordinates are used. There is one difference: instead of x and y, the parts of a graph instead are: v, for vertices, and e, for its edges.
The formal, mathematical definition for a graph is just this:
G = (V, E)What if our graph has more than one node and more than one edge! In fact…it will almost always have multiple edges if it has more than one node. How does this definition work in that case?
It works because that ordered pair — (V, E) — is actually made up of two objects: a set of vertices, and a set of edges.
Undirected Graph Illustration
In the example below, we have an undirected graph, with 8 vertices, and 11 edges.
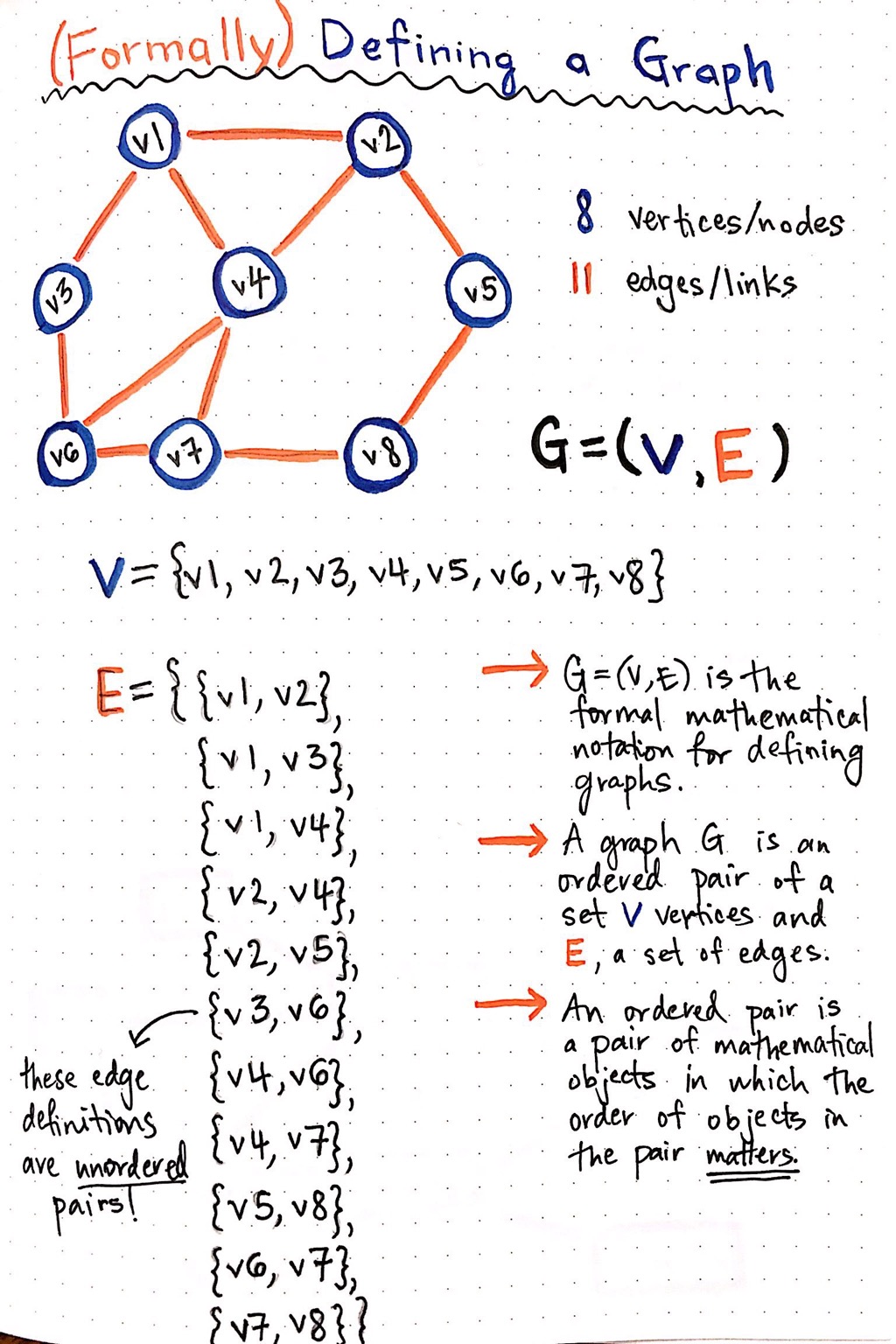
We wrote out our ordered pair (V, E), but because each of those items is an object, we had to write those out as well. We defined V as an unordered set of references to our 8 vertices. The “unordered” part is really important here, because remember, unlike trees, there is no hierarchy of nodes! Which means that we do not need to order them, since order does not matter here.
We also had to define E as an object, which contains multiple edge objects within it. Notice that our edge objects are also unordered. Why might that be? Well, what type of graph is this? Is there any direction or flow? Is there a fixed sense of “origin” and “destination”?
No, there is not! This is an undirected graph, which means that the edges are bidirectional and the origin node and destination node are not fixed. So, each of our edge objects are also unordered pairs.
We also had to define E as an object, which contains multiple edge objects within it. Notice that our edge objects are also unordered. Why might that be? Well, what type of graph is this? Is there any direction or flow? Is there a fixed sense of “origin” and “destination”?
No, there is not! This is an undirected graph, which means that the edges are bidirectional and the origin node and destination node are not fixed. So, each of our edge objects are also unordered pairs.
Directed Graph Illustration
Here is a directed graph, with three vertices and three edges:
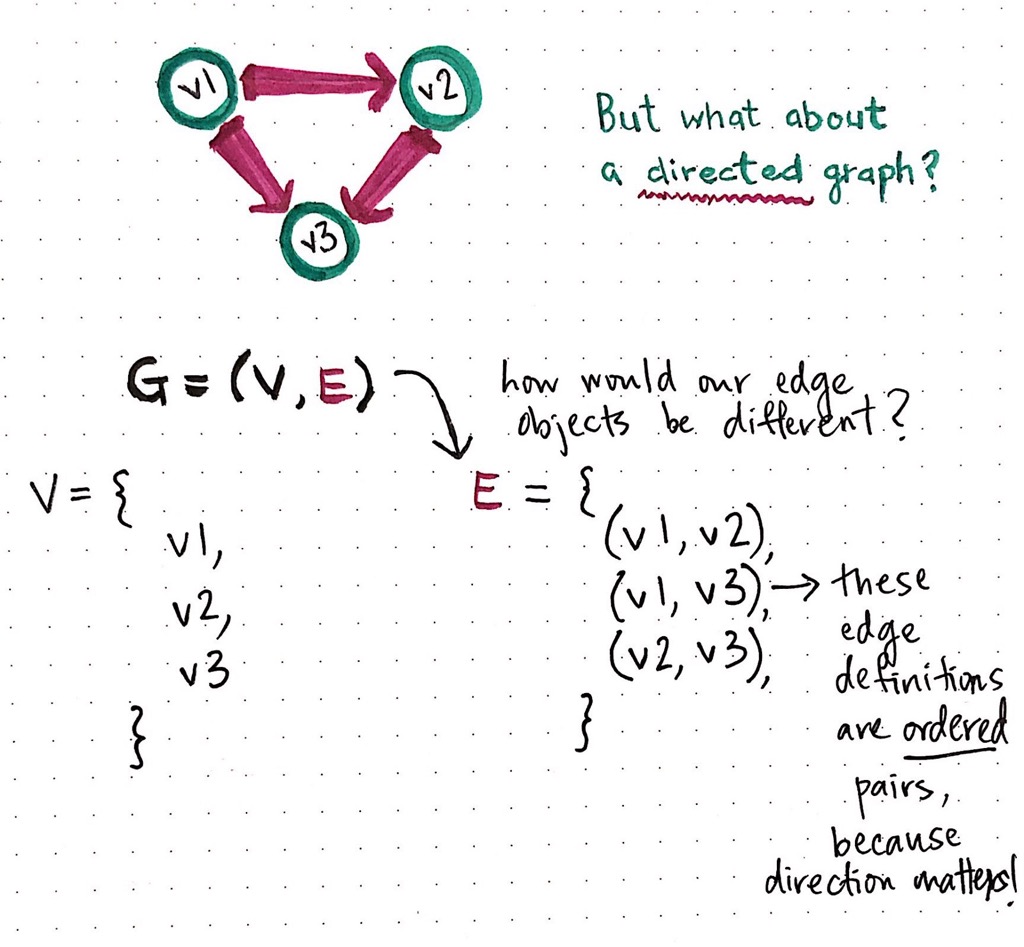
The way we define the vertices here does not look any different, but look more closely at our edge definition. Our edge objects in this case are ordered pairs, because direction matters in this case! Since we can only travel from the origin node to the destination node, our edges must be ordered, such that the origin node is the first of the two nodes in each of our edge definitions.
Applications
Applications
The world wide web (WWW) is a massive graph structure! When we click between websites and navigate back and forth between URLs, we are just navigating through a graph. Sometimes those graphs have nodes with edges that are undirected — you can go back and forth from one webpage to another — and others that are directed — you can only go from webpage A to webpage B, and never the other way around.
Facebook, a massive social network, is a type of graph. And if we think more about how it actually functions, we start to better understand how we can define, and exactly what type of graph it is. On Facebook, if person A adds person B as a friend, person B must accept the request from person A. It is not possible for person A to be person B's friend on the network without person B also being person A's. The relationship between two users (read: nodes or vertices in graph terms!) is bidirectional. There’s no concept of an “origin” and a “destination” node.
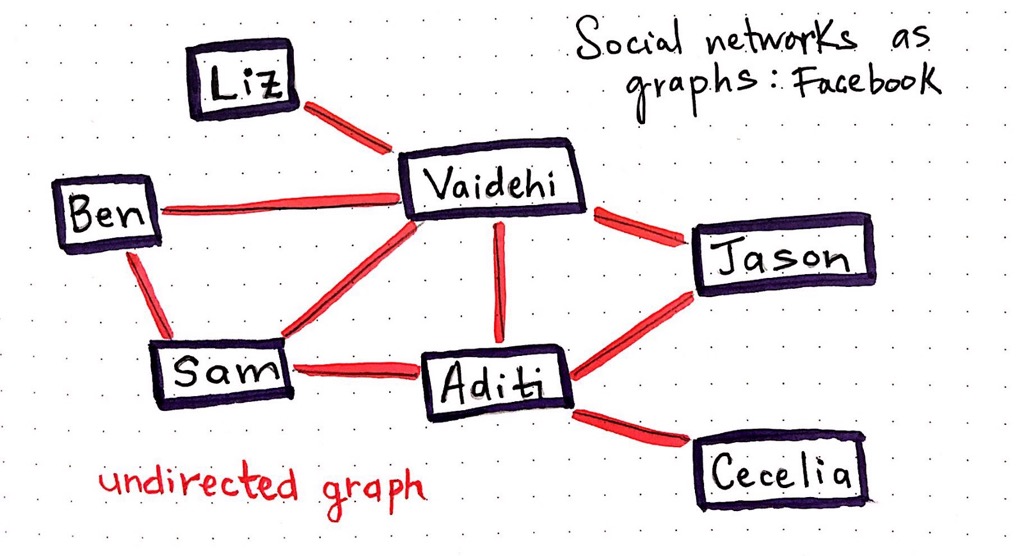
Relationships are two-way, so if we were to define Facebook’s friend network as a graph, its edges would all end up being unordered pairs when we wrote them out.
Twitter, on the other hand, works very differently from Facebook. Person A can follow person B, but it does not automatically follow that person B also follow person A back.
Twitter, on the other hand, works very differently from Facebook. Person A can follow person B, but it does not automatically follow that person B also follow person A back.
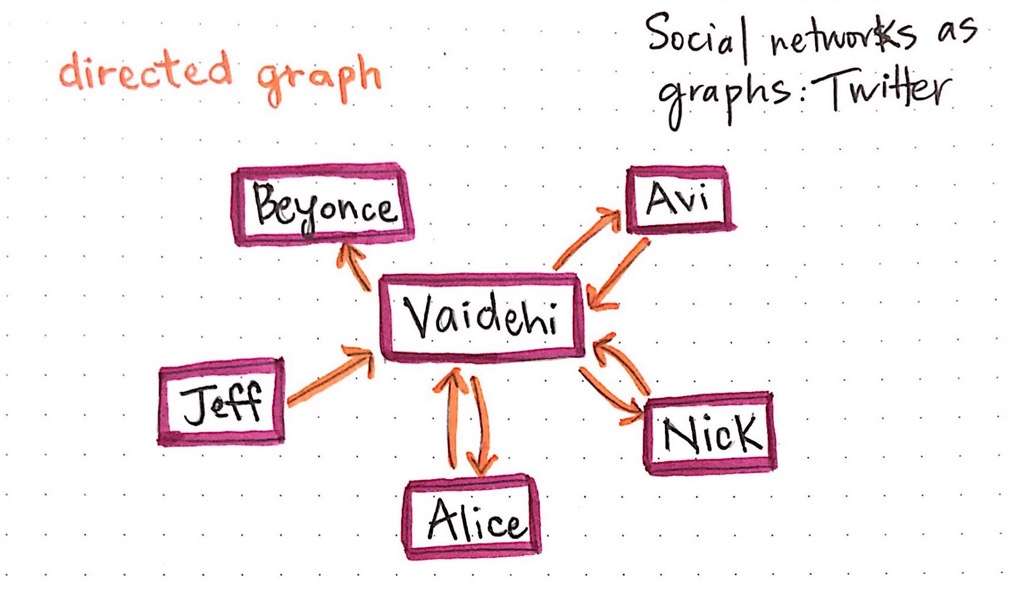
We could represent Twitter as a directed graph. Each edge we create represents a one-way relationship. When person A follows person B on Twitter, person A creates an edge in the graph with person B's account as the origin node, and person A's account as the destination node.
So what happens when person B follows person A back? Do we change the edge that was created when person A followed person B? Does it suddenly become bidirectional?
No, because person B could unfollow person A at any given point. When person B followed person A back on Twitter, person A created a second edge, with person A account as the origin node and person B as the destination.
The same model applies to Medium, as well, which lets you follow and unfollow authors! In fact, this network model is followed in plenty of domains. And all it is, once we abstract all the layers away, is a graph.
So what happens when person B follows person A back? Do we change the edge that was created when person A followed person B? Does it suddenly become bidirectional?
No, because person B could unfollow person A at any given point. When person B followed person A back on Twitter, person A created a second edge, with person A account as the origin node and person B as the destination.
The same model applies to Medium, as well, which lets you follow and unfollow authors! In fact, this network model is followed in plenty of domains. And all it is, once we abstract all the layers away, is a graph.
Representation
The two most commonly used representations of graph are the following:
There are other representations such as Incidence Matrix, Incidence List etc. The choice of the graph representation is context specific. It depends on the type of operations to be performed and ease of use of a representation within that context.
We will use the following simple graph to illustrate how to represent the data structure

Adjacency Matrix is a 2D array of size V x V where V is the number of vertices in a graph. Let the 2D array be
The adjacency matrix for the example graph presented above is:

Pros: Representation is easier to implement and follow. Removing an edge takes O(1) time. Queries such as whether there is an edge from vertex ‘
Cons: Consumes more space O(V2). Even if the graph is sparse(contains less number of edges), it consumes the same space. Adding a vertex is O(V2) time.
- Adjacency Matrix
- Adjacency List
There are other representations such as Incidence Matrix, Incidence List etc. The choice of the graph representation is context specific. It depends on the type of operations to be performed and ease of use of a representation within that context.
We will use the following simple graph to illustrate how to represent the data structure
Adjacency Matrix
Adjacency Matrix is a 2D array of size V x V where V is the number of vertices in a graph. Let the 2D array be
adj[][], a slot adj[i][j] = 1 indicates that there is an edge from vertex i to vertex j. Adjacency matrix for undirected graph is always symmetric. Adjacency Matrix is also used to represent weighted graphs. If adj[i][j] = w, then there is an edge from vertex i to vertex j with weight w.The adjacency matrix for the example graph presented above is:
Pros: Representation is easier to implement and follow. Removing an edge takes O(1) time. Queries such as whether there is an edge from vertex ‘
u’ to vertex ‘v’ are efficient and can be performed in O(1).Cons: Consumes more space O(V2). Even if the graph is sparse(contains less number of edges), it consumes the same space. Adding a vertex is O(V2) time.
Adjacency List
An array of linked lists is used as the underlying representation. Size of the array is equal to number of vertices. Let the array bearray[]. An entry array[i] represents the linked list of vertices adjacent to the ith vertex. This representation can also be used to represent a weighted graph. The weights of edges can be stored in nodes of linked lists. Following is the adjacency list representation of the graph presented above.
Pros: Saves space O(|V|+|E|) . In the worst case, there can be C(V, 2) number of edges in a graph thus consuming O(V2) space. Adding a vertex is a straightforward operation.
Cons: Queries such as whether there is an edge from vertex ‘
u’ to vertex ‘v’ are not efficient and can be performed in O(V).Breadth First Traversal
Breadth First Search (BFS) algorithm traverses a graph in a breadth-wise motion and uses a queue to track the next vertex to start a search, and when a dead end occurs in any iteration.
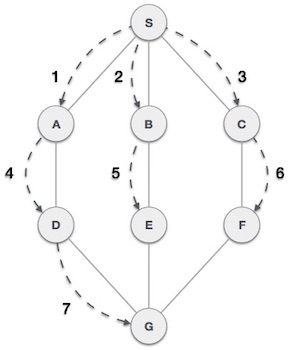
As in the example above, BFS algorithm traverses from A to B to E to F first then to C and G lastly to D. It employs the following rules:
As in the example above, BFS algorithm traverses from A to B to E to F first then to C and G lastly to D. It employs the following rules:
- Rule 1 − Visit the adjacent unvisited vertex. Mark it as visited. Display it. Insert it in a queue.
- Rule 2 − If no adjacent vertex is found, remove the first vertex from the queue.
- Rule 3 − Repeat Rule 1 and Rule 2 until the queue is empty.
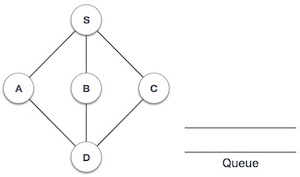
Initialise the queue.
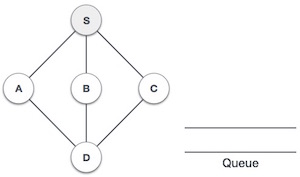
We start from visiting S(starting node), and mark it as visited.

We then see an unvisited adjacent node from S. In this example, we have three nodes but alphabetically we choose A, mark it as visited and enqueue it.
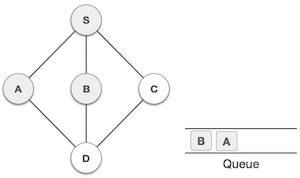
Next, the unvisited adjacent node from S is B. We mark it as visited and enqueue it.
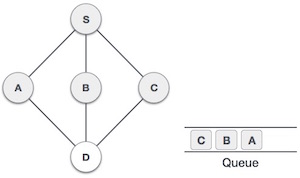
Next, the unvisited adjacent node from S is C. We mark it as visited and enqueue it.
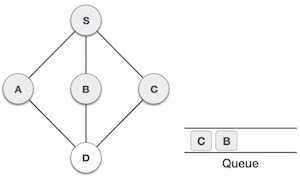
Now, S is left with no unvisited adjacent nodes. So, we dequeue and find A.
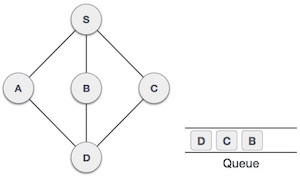
From A we have D as unvisited adjacent node. We mark it as visited and enqueue it.
At this stage, we are left with no unmarked (unvisited) nodes. As per the algorithm we keep on dequeuing in order to process all the unvisited nodes. When the queue is empty, the search is over.
A few common applications of breadth first traversal of graph data structures are:
Shortest Path and Minimum Spanning Tree for unweighted graph
In unweighted graph, the shortest path is the path with least number of edges. With Breadth First, we always reach a vertex from a given source vertex using the minimum number of edges.
Peer to Peer Networks
In Peer to Peer Networks like BitTorrent, Breadth First Search is used to find all the closed vertices (clients).
Crawlers in Search Engines
Crawlers build up their index using Breadth First. They start from the source page and follow all links from the source and keep doing same. Depth First Traversal can also be used for crawlers, but the advantage of Breadth First Traversal is that the depth or levels of the built tree can be limited.
Social Networking Websites
In social networks, we can find people within a given distance ‘k’ from a person using Breadth First Search till ‘k’ levels.
GPS Navigation systems
Breadth First Search is used to find all surrounding locations.
Broadcasting in Network
In networks, a broadcast packet follows Breadth First Search to reach all nodes.
In Garbage Collection
Breadth First Search is used in garbage collection using Cheney’s algorithm. BFS is preferred over DFS because of better locality of reference.
Cycle detection in undirected graph
In undirected graphs, either BFS or DFS can be used to detect cycles. For a directed graph, only depth first search can be used.
Applications
A few common applications of breadth first traversal of graph data structures are:
Shortest Path and Minimum Spanning Tree for unweighted graph
In unweighted graph, the shortest path is the path with least number of edges. With Breadth First, we always reach a vertex from a given source vertex using the minimum number of edges.
Peer to Peer Networks
In Peer to Peer Networks like BitTorrent, Breadth First Search is used to find all the closed vertices (clients).
Crawlers in Search Engines
Crawlers build up their index using Breadth First. They start from the source page and follow all links from the source and keep doing same. Depth First Traversal can also be used for crawlers, but the advantage of Breadth First Traversal is that the depth or levels of the built tree can be limited.
Social Networking Websites
In social networks, we can find people within a given distance ‘k’ from a person using Breadth First Search till ‘k’ levels.
GPS Navigation systems
Breadth First Search is used to find all surrounding locations.
Broadcasting in Network
In networks, a broadcast packet follows Breadth First Search to reach all nodes.
In Garbage Collection
Breadth First Search is used in garbage collection using Cheney’s algorithm. BFS is preferred over DFS because of better locality of reference.
Cycle detection in undirected graph
In undirected graphs, either BFS or DFS can be used to detect cycles. For a directed graph, only depth first search can be used.
Depth First Search
Depth First Search (DFS) algorithm traverses a graph in a depth-wise motion and uses a stack to track the next vertex to start a search, when a dead end occurs in any iteration.
As in the example given above, DFS algorithm traverses from S to A to D to G to E to B first, then to F and lastly to C. It employs the following rules.
- Rule 1 − Visit the adjacent unvisited vertex. Mark it as visited. Display it. Push it in a stack.
- Rule 2 − If no adjacent vertex is found, pop up a vertex from the stack. (It will pop up all the vertices from the stack, which do not have adjacent vertices.)
- Rule 3 − Repeat Rule 1 and Rule 2 until the stack is empty.
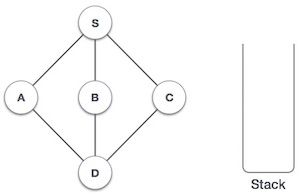
Initialise the stack.
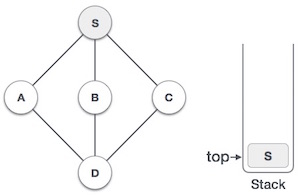
Mark S as visited and put it onto the stack. Explore any unvisited adjacent node from S. We have three nodes and we can pick any of them. For this example, we shall take the node in an alphabetical order.
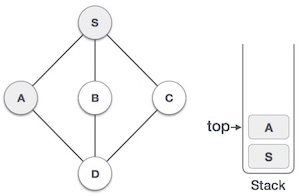
Mark A as visited and put it onto the stack. Explore any unvisited adjacent node from A. Both Sand D are adjacent to A but we are concerned for unvisited nodes only.
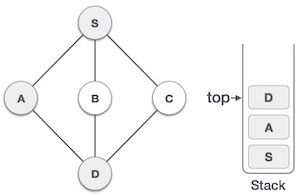
Visit D and mark it as visited and put onto the stack. Here, we have B and C nodes, which are adjacent to D and both are unvisited. However, we shall again choose in an alphabetical order.

We choose B, mark it as visited and put onto the stack. Here Bdoes not have any unvisited adjacent node. So, we pop Bfrom the stack.
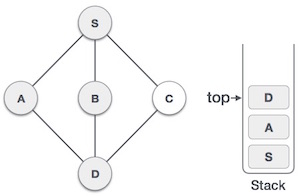
We check the stack top for return to the previous node and check if it has any unvisited nodes. Here, we find D to be on the top of the stack.
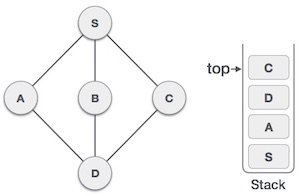
Only unvisited adjacent node is from D is C now. So we visit C, mark it as visited and put it onto the stack.
As C does not have any unvisited adjacent node so we keep popping the stack until we find a node that has an unvisited adjacent node. In this case, there is none and we keep popping until the stack is empty.
Following are a few common applications of DFS. Note that BFS is more commonly used for a wide variety of algorithms used in graph theory.
Minimum Spanning Tree of unweighted graph
For an unweighted graph, DFS traversal of the graph produces the minimum spanning tree and all pair shortest path tree.
Detecting cycles in a graph
A graph has cycles if and only if we see a back/reverse edge during DFS. Hence DFS is used to check for back/reverse edges.
Path Finding
We can adapt the DFS algorithm to find a path between two given vertices u and z.
Topological Sorting
Topological Sorting is mainly used for scheduling jobs from the given dependencies among jobs. In computer science, applications of this type arise in instruction scheduling, ordering of formula cell evaluation when recomputing formula values in spreadsheets, logic synthesis, determining the order of compilation tasks to perform in makefiles, data serialisation, and resolving symbol dependencies in linkers.
Finding Strongly Connected Components of a graph
A directed graph is called strongly connected if there is a path from each vertex in the graph to every other vertex.
Solving puzzles with only one solution, such as mazes
DFS can be adapted to find the unique solution to a maze by only including nodes on the current path in the visited set.
Applications
Following are a few common applications of DFS. Note that BFS is more commonly used for a wide variety of algorithms used in graph theory.
Minimum Spanning Tree of unweighted graph
For an unweighted graph, DFS traversal of the graph produces the minimum spanning tree and all pair shortest path tree.
Detecting cycles in a graph
A graph has cycles if and only if we see a back/reverse edge during DFS. Hence DFS is used to check for back/reverse edges.
Path Finding
We can adapt the DFS algorithm to find a path between two given vertices u and z.
- Call DFS with u as the start vertex.
- Use a stack S to keep track of the path between the start vertex and the current vertex.
- As soon as destination vertex z is encountered, return the path as the contents of the stack
Topological Sorting
Topological Sorting is mainly used for scheduling jobs from the given dependencies among jobs. In computer science, applications of this type arise in instruction scheduling, ordering of formula cell evaluation when recomputing formula values in spreadsheets, logic synthesis, determining the order of compilation tasks to perform in makefiles, data serialisation, and resolving symbol dependencies in linkers.
Finding Strongly Connected Components of a graph
A directed graph is called strongly connected if there is a path from each vertex in the graph to every other vertex.
Solving puzzles with only one solution, such as mazes
DFS can be adapted to find the unique solution to a maze by only including nodes on the current path in the visited set.
References
https://medium.com/basecs/a-gentle-introduction-to-graph-theory-77969829ead8
https://www.geeksforgeeks.org/graph-and-its-representations/
https://www.tutorialspoint.com/data_structures_algorithms/breadth_first_traversal.htm
https://www.tutorialspoint.com/data_structures_algorithms/depth_first_traversal.htm