Lesson 7 - Circular Buffers
Circular buffers are fixed-size buffers that work as if the memory is contiguous and circular in nature. As memory is generated and consumed, data does not need to be reshuffled - rather, the head/tail pointers are adjusted. When data is added, the head pointer advances. When data is consumed, the tail pointer advances. If you reach the end of the buffer, you simply wrap around to the beginning and continue moving.
Due to the resource constrained nature of embedded systems, circular buffer data structures are commonly used. Commonly a circular buffer is used in logging infrastructure: as the buffer fills up, the oldest log data is overwritten by the newest data.
Details
The ring buffer is a circular software queue. This queue has a first-in-first-out (FIFO) data characteristic. These buffers are quite common and are found in many embedded systems. Usually, most developers write these constructs from scratch on an as-needed basis.
The C++ language has the Standard Template Library (STL), which has a very easy-to-use set of class templates. This library enables the developer to create the queue and other lists relatively easily.
The ring buffer usually has two indices to the elements within the buffer. The distance between the indices can range from zero (0) to the total number of elements within the buffer. The use of the dual indices means the queue length can shrink to zero, (empty), to the total number of elements, (full). Figure shows the ring structure of the ring buffer, (FIFO) queue.
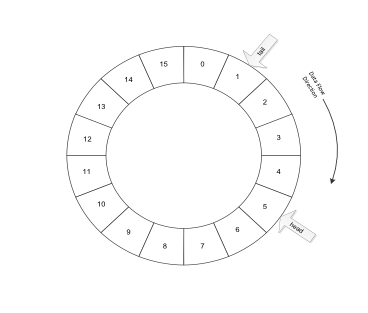
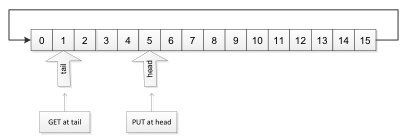
The data gets PUT at the head index, and the data is read from the tail index. In essence, the newest data "grows" from the head index. The oldest data gets retrieved from the tail index. Figure shows how the head and tail index varies in time using a linear array of elements for the buffer.
Use cases
Single process to single process
In general, the queue is used to serialise data from one process to another process. The serialisation allows some elasticity in time between the processes. In many cases, the queue is used as a data buffer in some hardware interrupt service routine. This buffer will collect the data so that at some later time another process can fetch the data for further processing. This use case is the single process to process buffering case.
This use case is typically found as an interface between some very high priority hardware service buffering data to some lower priority service running in some background loop. This simple buffering use case is shown in Figure.
In many cases, there will be a need for two queues for a single interrupt service. Using multiple queues is quite common for device drivers for serial devices such as RS-232, I2C or USB drivers.
Single process to multiple processes
The least common use case is the single process to multiple processes case. The difficulty here is to determine where to steer the output in real time. Usually, this is done by tagging the data elements in such a way that a broker can steer the data in some meaningful way. Figure shows the single process to multiple processes use case. Since queues can be readily created, it is usually better to create multiple queues to solve this use case than it would be to use a single queue.

Figure shows how to reorganize the single process to multiple process use case using a set of cascaded queues. In this case, we have inserted an Rx / Tx Broker Dispatcher service, which will parse the incoming requests to each of the individual process queues.

Implementation Note
Both the "full" and "empty" cases of the circular buffer look the same: head and tail pointer are equal.
One common technique to simplify the implementation is to waste one slot in the buffer to differentiate between full
(tail + 1 == head) and empty (head == tail). This resource waste is not required, but avoiding it does require additional logic.Another alternative strategy is to use a bool to indicate whether the buffer is empty. The empty flag should only be set during initialisation and by the dequeue operation. The empty flag should only be cleared when data is added during the enqueue operation.
With the empty flag, you can differentiate between the two cases easily:
empty:
(head == tail) && empty
full:
(head == tail) && !empty