Lesson 6 - Object Oriented Programming
A deeper look at OOP concepts such an inheritance, composition and friendship.
Friendship
In principle, private and protected members of a class cannot be accessed from outside the same class in which they are declared. However, this rule does not apply to friends.
Friends are functions or classes declared with the friend keyword.
Friend Functions
A non-member function can access the private and protected members of a class if it is declared a friend of that class. That is done by including a declaration of this external function within the class, and preceding it with the keyword friend:
#include <iostream>
class Rectangle
{
int width, height;
public:
Rectangle() {}
Rectangle( int x, int y ) : width{x}, height{y} {}
int area() const { return width * height; }
friend Rectangle duplicate( const Rectangle& );
};
Rectangle duplicate( const Rectangle& rect )
{
Rectangle copy;
copy.width = rect.width * 2;
copy.height = rect.height * 2;
return copy;
}
int main()
{
const Rectangle bar{ 2, 3 };
const Rectangle foo = duplicate( bar );
std::cout << foo.area() << std::endl;
return 0;
}
The duplicate function is a friend of class Rectangle. Therefore, function duplicate has access to width and height (which are private) of different objects of type Rectangle.
Typical use cases of friend functions are operations that are conducted between two different classes accessing private or protected members of both.
Friend classes
Similar to friend functions, a friend class is a class whose members have access to the private or protected members of another class:
class Square;
class Rectangle
{
public:
int area() const {return (width * height);}
void convert(const Square& a);
private:
int width, height;
};
class Square
{
friend class Rectangle;
public:
Square(int a) : side{a} {}
private:
int side;
};
void Rectangle::convert(const Square& a)
{
width = a.side;
height = a.side;
}
int main()
{
Rectangle rect;
Square sqr{4};
rect.convert(sqr);
return 0;
}
Rectangle is a friend of Square allowing Rectangle's member functions to access private and protected members of Square. Rectangle accesses the member variable Square::side, which describes the side of the square.
Friendships are never corresponded unless specified: Rectangle is considered a friend class by Square, but Square is not considered a friend by Rectangle. The member functions of Rectangle can access the protected and private members of Square but not vice versa. Square could also be declared friend of Rectangle.
Friendships are not transitive: The friend of a friend is not considered a friend unless explicitly specified.
Inheritance
Classes in C++ can be extended, creating new classes which retain characteristics of the base class. This process, known as inheritance, involves a base class and a derived class(es). The derived class inherits the members of the base class, on top of which it can add its own members.
Imagine a series of classes to describe two kinds of polygons: rectangles and triangles. These two polygons have certain common properties, such as the values needed to calculate their areas: they both can be described simply with a height and a width (or base).
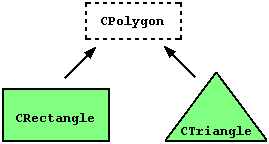
The Polygon class would contain members that are common for both types of polygon. In our example - width and height. Rectangle and Triangle would be its derived classes, with specific features that are different from one type of polygon to the other.
Classes that are derived from others inherit all the accessible members of the base class. That means that if a base class includes a member
A and we derive a class from it with another member called B, the derived class will contain both member A and member B.The inheritance relationship of two classes is declared in the derived class. Derived classes definitions use the following syntax:
class derived_class_name: public base_class_name
{ /*...*/ };
Where derived_class_name is the name of the derived class and base_class_name is the name of the class on which it is based. The public access specifier may be replaced by any one of the other access specifiers (protected or private). This access specifier limits the most accessible level for the members inherited from the base class: The members with a more accessible level are inherited with this level instead, while the members with an equal or more restrictive access level keep their restrictive level in the derived class.
class Polygon
{
public:
void setValues(int a, int b) {width=a; height=b;}
protected:
int getWidth() const { return width; }
int getHeight() const { return height; }
private:
int width, height;
};
class Rectangle: public Polygon
{
public:
int area() { return getWidth() * getHeight(); }
};
class Triangle: public Polygon
{
public:
float area() { return getWidth() * getHeight() / 2.0; }
};
int main()
{
Rectangle rect;
Triangle trgl;
rect.setValues(4,5);
trgl.setValues(4,5);
rect.area();
trgl.area();
return 0;
}
The objects of the classes Rectangle and Triangle each contain members inherited from Polygon. These are: getWidth, getHeight and setValues.
The protected access specifier used in class Polygon is similar to private. The only difference applies to inheritance: When a class inherits another one, the members of the derived class can access the protected members inherited from the base class, but not its private members.
By declaring getWidth and getHeight as protected instead of private, these members are also accessible from the derived classes Rectangle and Triangle, instead of just from members of Polygon. If they were public, they could be accessed from anywhere.
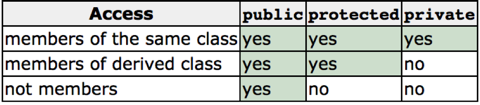
Where "not members" represents any access from outside the class, such as from
main, from another class or from a function.In the example above, the members inherited by Rectangle and Triangle have the same access permissions as they had in their base class Polygon:
Polygon::getWidth // protected access
Rectangle::getWidth // protected access
Polygon::setValues() // public access
Rectangle::setValues() // public access
This is because the inheritance relation has been declared using the public keyword on each of the derived classes:
class Rectangle: public Polygon { /* ... */ }
This public keyword after the colon(:) denotes the most accessible level the members inherited from the class that follows it (in this case Polygon) will have from the derived class (in this case Rectangle). Since public is the most accessible level, by specifying this keyword the derived class will inherit all the members with the same levels they had in the base class.
With protected, all public members of the base class are inherited as protected in the derived class. Conversely, if the most restricting access level is specified (private), all the base class members are inherited as private.
For example, if Daughter were a class derived from Mother that we defined as:
class Daughter: protected Mother;
This would set protected as the less restrictive access level for the members of Daughter that it inherited from Mother. That is, all members that were public in Mother would become protected in Daughter. This would not restrict Daughter from declaring its own public members. That less restrictive access level is only set for the members inherited from Mother.
If no access level is specified for the inheritance, the compiler assumes private for classes declared with keyword class and public for those declared with struct.
Most use cases of inheritance in C++ should use public inheritance. When other access levels are needed for base classes, they can usually be better represented as member variables instead (composition).
What is inherited from the base class?
In principle, a publicly derived class inherits access to every member of a base class except:
- its constructors and its destructor
- its assignment operator members (operator=)
- its friends
- its private members
Even though access to the constructors and destructor of the base class is not inherited as such, they are automatically called by the constructors and destructor of the derived class.
Unless otherwise specified, the constructors of a derived class calls the default constructor of its base classes (i.e., the constructor taking no arguments). Calling a different constructor of a base class is possible, using the same syntax used to initialise member variables in the initialisation list:
derived_constructor_name (parameters) : base_constructor_name (parameters) {...}
#include <iostream>
class Mother
{
public:
Mother() { std::cout << "Mother: no parameters" << std::endl; }
Mother(int a) { std::cout << "Mother: int parameter" << std::endl; }
};
class Daughter : public Mother
{
public:
Daughter(int a) { std::cout << "Daughter: int parameter" << std::endl; }
};
class Son : public Mother
{
public:
Son(int a) : Mother{a} { std::cout << "Son: int parameter" << std::endl; }
};
int main()
{
Daughter kelly{0};
Son bud{0};
return 0;
}
Inheriting Constructors
If the using-declaration refers to a constructor of a direct base of the class being defined (e.g. using Base::Base;), constructors of that base class are inherited, according to the following rules:
- A set of candidate inheriting constructors is composed of
- All non-template constructors of the base class (after omitting ellipsis parameters, if any) (since C++14)
- For each constructor with default arguments or the ellipsis parameter, all constructor signatures that are formed by dropping the ellipsis and omitting default arguments from the ends of argument lists one by one
- All constructor templates of the base class (after omitting ellipsis parameters, if any) (since C++14)
- For each constructor template with default arguments or the ellipsis, all constructor signatures that are formed by dropping the ellipsis and omitting default arguments from the ends of argument lists one by one
All candidate inherited constructors that aren't the default constructor or the copy/move constructor and whose signatures do not match user-defined constructors in the derived class, are implicitly declared in the derived class. The default parameters are not inherited
The inherited constructors are equivalent to user-defined constructors with an empty body and with a member initialiser list consisting of a single nested-name-specifier, which forwards all of its arguments to the base class constructor.
It has the same access as the corresponding base constructor. It is constexpr if the user-defined constructor would have satisfied constexpr constructor requirements. It is deleted if the corresponding base constructor is deleted or if a defaulted default constructor would be deleted (except that the construction of the base whose constructor is being inherited doesn't count). An inheriting constructor cannot be explicitly instantiated or explicitly specialised.
struct B1 {
B1(int);
};
struct D1 : B1 {
using B1::B1;
// The set of candidate inherited constructors is
// 1. B1(const B1&)
// 2. B1(B1&&)
// 3. B1(int)
// D1 has the following constructors:
// 1. D1()
// 2. D1(const D1&)
// 3. D1(D1&&)
// 4. D1(int) <- inherited
};
struct B2 {
B2(int = 13, int = 42);
};
struct D2 : B2 {
using B2::B2;
// The set of candidate inherited constructors is
// 1. B2(const B2&)
// 2. B2(B2&&)
// 3. B2(int = 13, int = 42)
// 4. B2(int = 13)
// 5. B2()
// D2 has the following constructors:
// 1. D2()
// 2. D2(const D2&)
// 3. D2(D2&&)
// 4. D2(int, int) <- inherited
// 5. D2(int) <- inherited
};
Multiple inheritance
A class may inherit from more than one class by simply specifying more base classes, separated by commas, in the list of a class's base classes (i.e., after the colon). For example, if the program had a specific class to print on screen called Output, and we wanted our classes Rectangle and Triangle to also inherit its members in addition to those of Polygon we could write:
class Rectangle: public Polygon, public Output;
class Triangle: public Polygon, public Output;
#include <iostream>
class Polygon
{
protected:
const int width;
const int height;
public:
Polygon(int a, int b) : width{a}, height{b} {}
};
class Output
{
public:
inline static void print(int i)
{
std::cout << i << std::endl;
}
};
class Rectangle: public Polygon, public Output
{
public:
Rectangle(int a, int b) : Polygon{a,b} {}
int area() const { return width*height; }
};
class Triangle: public Polygon, public Output
{
public:
Triangle(int a, int b) : Polygon{a,b} {}
float area() const { return width*height/2.0; }
};
int main()
{
Rectangle rect{4,5};
Triangle trgl{4,5};
rect.print(rect.area());
Triangle::print(trgl.area());
return 0;
}
Polymorphism
One of the key features of class inheritance is that a pointer to a derived class is type-compatible with a pointer to its base class. Polymorphism is the art of taking advantage of this simple but powerful and versatile feature.
int main()
{
Rectangle rect;
Triangle trgl;
Polygon* ppoly1 = ▭
Polygon* ppoly2 = &trgl;
ppoly1->set_values(4,5);
ppoly2->set_values(4,5);
return 0;
}
Function main declares two pointers to Polygon (named ppoly1 and ppoly2). These are assigned the addresses of rect and trgl, which are objects of type Rectangle and Triangle respectively. Such assignments are valid, since both Rectangle and Triangle are classes derived from Polygon.
Dereferencing ppoly1 and ppoly2 (with *ppoly1 and *ppoly2) is valid and allows us to access the members of their pointed objects. For example, the following two statements would be equivalent in the previous example:
ppoly1->set_values(4,5);
rect.set_values(4,5);
Since the type of ppoly1 and ppoly2 is pointer to Polygon (and not pointer to Rectangle nor pointer to Triangle), only the members inherited from Polygon can be accessed, and not those of the derived classes Rectangle and Triangle.
Virtual members
A virtual member is a member function that can be redefined in a derived class, while preserving it’s calling properties through references (tells the compiler to perform Late Binding on this function). In Late Binding the function call is resolved at runtime (instead of compile time). The compiler determines the type of object at runtime, and then binds the function call. Late Binding is also called Dynamic Binding or Runtime Binding.
The syntax for a function to become virtual is to precede its declaration with the virtual keyword. The following additional keywords are also supported to ensure and control the scope of virtual functions.
- override - In a member function declaration or definition,
overrideensures that the function isvirtualand is overriding a virtual function from the base class. The program is ill-formed (a compile-time error is generated) if this is not true (wrong function signature usually). override` is an identifier with a special meaning when used after member function declarators: it is not a reserved keyword otherwise. - final - Specifies that a
virtualfunction cannot be overridden in a derived class or that a class cannot be inherited from.
#include <iostream>
#include <iomanip>
class Polygon
{
public:
Polygon( int width, int height ) : width{ width }, height{ height } {}
virtual float area() const { return 0; }
protected:
const int width;
const int height;
};
class Rectangle: public Polygon
{
public:
Rectangle( int width, int height ) : Polygon{ width, height } {}
float area() const override final { return width * height; }
};
class Triangle: public Polygon
{
public:
Triangle( int width, int height ) : Polygon{ width, height } {}
float area() const override final { return (width * height / 2.0); }
};
int main()
{
Rectangle rect{4,5};
Triangle trgl{4,5};
Polygon poly{4,5};
Polygon* ppoly1 = ▭
Polygon* ppoly2 = &trgl;
Polygon* ppoly3 = &poly;
std::cout << std::fixed << std::setprecision( 1 );
std::cout << "Area of rectangle: " << ppoly1->area() << std::endl;
std::cout << "Area of triangle: " << ppoly2->area() << std::endl;
std::cout << "Area of polygon: " << ppoly3->area() << std::endl;
return 0;
}
The member function area has been declared as virtual in the base class because it is later redefined in each of the derived classes. Non-virtual members can also be redefined in derived classes, but non-virtual members of derived classes cannot be accessed through a reference of the base class: i.e., if virtual is removed from the declaration of area in the example above, all three calls to area would return zero, because in all cases, the version of the base class would have been called instead.
A class that declares or inherits a virtual function is called a polymorphic class. In general destructor functions are almost always declared virtual.
Mechanics of Late Binding
To accomplish late binding, the compiler creates VTABLEs, for each class with virtual function(s). The address of virtual functions is inserted into these tables. Whenever an object of a polymorphic class is created the compiler implicitly inserts a pointer called vpointer, pointing to VTABLE for that object. When the function is invoked, the compiler is able to resolve the call by binding the correct function using the vpointer.
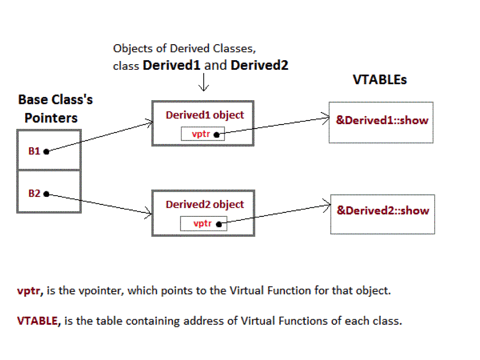
1. Only the Base class function(s) declaration need the
virtual keyword, not the definition.2. If a function is declared as virtual in the base class, it will be virtual in all its derived classes.
3. The address of the virtual function is placed in the VTABLE and the compiler uses VPTR (vpointer) to point to the virtual function.
Abstract base classes
Abstract base classes are very similar to the Polygon class in the previous example. They are classes that can only be used as base classes (cannot be instantiated), and thus are allowed to have virtual member functions without definition (known as pure virtual functions). The syntax is to declare the pure virtual function and define it as equal to zero (note that it has to be
0 and not nullptr or any other alias).#include <iostream>
#include <iomanip>
#include <memory>
class Polygon
{
protected:
const int width;
const int height;
Polygon(int width, int height) : width{width}, height{height} {}
public:
virtual ~Polygon() {}
virtual float area() const = 0;
inline void printarea() const
{
std::cout << "Area of polygon: " << area() << std::endl;
}
};
class Rectangle: public Polygon
{
public:
Rectangle( int width, int height ) : Polygon{ width, height } {}
float area() const { return width * height; }
};
class Triangle: public Polygon
{
public:
Triangle( int width, int height ) : Polygon{ width, height } {}
float area() const { return (width * height / 2.0); }
};
int main()
{
std::unique_ptr<Polygon> ppoly1 = std::make_unique<Rectangle>( 4, 5 );
std::unique_ptr<Polygon> ppoly2 = std::make_unique<Triangle>( 4, 5 );
std::cout << std::fixed << std::setprecision( 1 );
ppoly1->printarea();
ppoly2->printarea();
return 0;
}
The function area has no definition; this has been replaced by = 0, which makes it a pure virtual function. Classes that contain at least one pure virtual function are known as abstract base classes.
Abstract base classes cannot be used to instantiate objects. Therefore, this last abstract base class version of Polygon could not be used to declare objects like:
```c++ Polygon mypolygon; // will not compile if Polygon is abstract base class
But an abstract base class is not totally useless. It can be used to create pointers to it, and take advantage of its polymorphic abilities.
Objects of different but related types are referred to using a common type of pointer (Polygon*) and the proper member function is called every time, because they are virtual (referred to as run-time binding). It is even possible for a member of the abstract base class Polygon to use the special pointer this to access the proper virtual members, even though Polygon itself has no implementation for this function.
Virtual members and abstract classes grant C++ polymorphic characteristics, most useful for object-oriented projects. These features can be applied to containers of objects or dynamically allocated objects.
Notice that the ppoly pointers are declared being of type "pointer to Polygon", but the objects allocated have been declared having the derived class type directly (Rectangle and Triangle).
Composition
In real-life, complex objects are often built from smaller, simpler objects. For example, a car is built using a metal frame, an engine, some tyres, a transmission, a steering wheel, and a large number of other parts. A personal computer is built from a CPU, a motherboard, some memory, etc… Even you are built from smaller parts: you have a head, a body, some legs, arms, and so on. This process of building complex objects from simpler ones is called object composition.
Broadly speaking, object composition models a “has-a” relationship between two objects. A car “has-a” transmission. Your computer “has-a” CPU. You “have-a” heart. The complex object is sometimes called the whole, or the parent. The simpler object is often called the part, child, or component.
In C++, you’ve already seen that structs and classes can have data members of various types (such as fundamental types or other classes). When we build classes with data members, we’re essentially constructing a complex object from simpler parts, which is object composition. For this reason, structs and classes are sometimes referred to as composite types.
Object composition is useful in a C++ context because it allows us to create complex classes by combining simpler, more easily manageable parts. This reduces complexity, and allows us to write code faster and with less errors because we can reuse code that has already been written, tested, and verified as working.
Types of object composition
There are two basic subtypes of object composition: composition and aggregation.
Composition
To qualify as a composition, an object and a part must have the following relationship:
- The part (member) is part of the object (class)
- The part (member) can only belong to one object (class) at a time
- The part (member) has its existence managed by the object (class)
- The part (member) does not know about the existence of the object (class)
A good real-life example of a composition is the relationship between a person’s body and a heart. Let us examine these in more detail.
Composition relationships are part-whole relationships where the part must constitute part of the whole object. For example, a heart is a part of a person’s body. The part in a composition can only be part of one object at a time. A heart that is part of one person’s body cannot be part of someone else’s body at the same time.
In a composition relationship, the object is responsible for the existence of the parts. Most often, this means the part is created when the object is created, and destroyed when the object is destroyed. But more broadly, it means the object manages the part’s lifecycle in such a way that the user of the object does not need to get involved. For example, when a body is created, the heart is created too. When a person’s body is destroyed, their heart is destroyed too. Because of this, composition is sometimes called a “death relationship”.
And finally, the part does not know about the existence of the whole. Your heart operates blissfully unaware that it is part of a larger structure. We call this a unidirectional relationship, because the body knows about the heart, but not the other way around.
Note that composition has nothing to say about the transferability of parts. A heart can be transplanted from one body to another. However, even after being transplanted, it still meets the requirements for a composition (the heart is now owned by the donor, and can only be part of the donor object unless transferred again).
class Fraction
{
private:
int numerator;
int denominator;
public:
Fraction(int numerator=0, int denominator=1): numerator{numerator}, denominator{denominator} {}
};
This class has two data members: a numerator and a denominator. The numerator and denominator are part of the Fraction (contained within it). They cannot belong to more than one Fraction at a time. The numerator and denominator do not know they are part of a Fraction, they just hold integers. When a Fraction instance is created, the numerator and denominator are created. When the fraction instance is destroyed, the numerator and denominator are destroyed as well.
While object composition models has-a type relationships (a body has-a heart, a fraction has-a denominator), we can be more precise and say that composition models “part-of” relationships (a heart is part-of a body, a numerator is part of a fraction). Composition is often used to model physical relationships, where one object is physically contained inside another.
The parts of a composition can be singular or multiplicative -- for example, a heart is a singular part of the body, but a body contains 10 fingers (which could be modelled as a std::array).
Implementing compositions
Compositions are one of the easiest relationship types to implement in C++. They are typically created as structs or classes with normal data members. Because these data members exist directly as part of the struct/class, their lifetimes are bound to that of the class instance itself.
Compositions that need to do dynamic allocation or deallocation may be implemented using pointer data members. In this case, the composition should be responsible for doing all necessary memory management itself.
In general, if you can design a class using composition, you should design a class using composition. Classes designed using composition are straightforward, flexible, and robust (in that they clean up after themselves nicely).
#include <iostream>
class Point2D
{
private:
int x;
int y;
public:
// A default constructor
Point2D() : x(0), y(0) {}
// A specific constructor
Point2D(int x, int y) : x(x), y(y) {}
// An overloaded output operator
friend std::ostream& operator<<(std::ostream& out, const Point2D &point)
{
out << "(" << point.x << ", " << point.y << ")";
return out;
}
// Access functions
void setPoint(int xc, int yc)
{
x = xc;
y = yc;
}
};
class Creature
{
private:
std::string name;
Point2D location;
public:
Creature(std::string name, const Point2D &location) : name(name), location(location) {}
friend std::ostream& operator<<(std::ostream& out, const Creature &creature)
{
out << creature.name << " is at " << creature.location;
return out;
}
void moveTo(int x, int y)
{
location.setPoint(x, y);
}
};
Variants on the composition theme
Although most compositions directly create their parts when the composition is created and directly destroy their parts when the composition is destroyed, there are some variations of composition that bend these rules a bit. For example:
- A composition may defer creation of some parts until they are needed. For example, a string class may not create a dynamic array of characters until the user assigns the string some data to hold.
- A composition may opt to use a part that has been given to it as input rather than create the part itself.
- A composition may delegate destruction of its parts to some other object (e.g. to a garbage collection routine).
The key point here is that the composition should manage its parts without the user of the composition needing to manage anything.
Composition and subclasses
One question that new programmers often ask when it comes to object composition is, “When should I use a subclass instead of direct implementation of a feature?”. For example, instead of using the Point2D class to implement the Creature’s location, we could have instead just added 2 integers to the Creature class and written code in the Creature class to handle the positioning. However, making Point2D its own class has a number of benefits:
- Each individual class can be kept relatively simple and straightforward, focused on performing one task well. This makes those classes easier to write and much easier to understand, as they are more focused. For example, Point2D only worries about point-related stuff, which helps keep it simple.
- Each subclass can be self-contained, which makes them reusable. For example, we could reuse our Point2D class in a completely different application. Or if our creature ever needed another point (for example, a destination it was trying to get to), we can simply add another Point2D member variable.
- The parent class can have the subclasses do most of the hard work, and instead focus on coordinating the data flow between the subclasses. This helps lower the overall complexity of the parent object, because it can delegate tasks to its children, who already know how to do those tasks. For example, when we move our Creature, it delegates that task to the Point2D class, which already understands how to set a point. Thus, the Creature class does not have to worry about how such things would be implemented.
A good rule of thumb is that each class should be built to accomplish a single task. That task should either be the storage and manipulation of some kind of data (e.g. Point2D, std::string), OR the coordination of subclasses (e.g. Creature). Ideally, not both.
In our example, it makes sense that Creature should not have to worry about how Points are implemented, or how the name is being stored. Creature’s job isn’t to know those intimate details. Creature’s job is to worry about how to coordinate the data flow and ensure that each of the subclasses knows what it is supposed to do. It is up to the individual subclasses to worry about how they will do it.
Aggregation
To quality as an aggregation, a whole object and its parts must have the following relationship:
- The part (member) is part of the object (class)
- The part (member) can belong to more than one object (class) at a time
- The part (member) does not have its existence managed by the object (class)
- The part (member) does not know about the existence of the object (class)
Like a composition, an aggregation is still a part-whole relationship, where the parts are contained within the whole, and it is a unidirectional relationship. However, unlike a composition, parts can belong to more than one object at a time, and the whole object is not responsible for the existence and lifespan of the parts. When an aggregation is created, the aggregation is not responsible for creating the parts. When an aggregation is destroyed, the aggregation is not responsible for destroying the parts.
For example, consider the relationship between a person and their home address. In this example, for simplicity, we’ll say every person has an address. However, that address can belong to more than one person at a time: for example, to both you and your roommate or other members of your family. However, that address isn’t managed by the person -- the address probably existed before the person got there, and will exist after the person is gone. Additionally, a person knows what address they live at, but the addresses do not know what people live there. Therefore, this is an aggregate relationship.
Alternatively, consider a car and an engine. A car engine is part of the car. And although the engine belongs to the car, it can belong to other things as well, like the person who owns the car. The car is not responsible for the creation or destruction of the engine. And while the car knows it has an engine (it has to in order to get anywhere) the engine does not know it is part of the car.
When it comes to modelling physical objects, the use of the term “destroyed” can be a little tricky. One might argue, “If a meteor fell out of the sky and crushed the car, wouldn’t the car parts all be destroyed too?” Yes, of course, but that is the fault of the meteor. The important point is that the car is not responsible for destruction of its parts (but an external force might be).
We can say that aggregation models “has-a” relationships (a department has teachers, the car has an engine).
Similar to a composition, the parts of an aggregation can be singular or multiplicative.
Implementing aggregations
Because aggregations are similar to compositions in that they are both part-whole relationships, they are implemented almost identically, and the difference between them is mostly semantic. In a composition, we typically add our parts to the composition using either normal member variables (or pointers where the allocation and deallocation process is handled by the composition class).
In an aggregation, we also add parts as member variables. However, these member variables are typically either references or pointers that are used to point at objects that have been created outside the scope of the class. Consequently, an aggregation usually either takes the objects it is going to point to as constructor parameters, or it begins empty and the sub-objects are added later via access functions or operators.
Because these parts exist outside of the scope of the class, when the class is destroyed, the pointer or reference member variable will be destroyed (but not deleted). Consequently, the parts themselves will still exist.
Let us take a look at a Teacher and Department example in more detail. In this example, we’re going to make a couple of simplifications: First, the department will only hold one teacher. Second, the teacher will be unaware of what department they are part of.
#include <string>
class Teacher
{
private:
std::string name;
public:
Teacher(std::string name) : name(name) {}
const std::string getName() const { return name; }
};
class Department
{
private:
Teacher *teacher; // This dept holds only one teacher for simplicity, but it could hold many teachers
public:
Department(Teacher* teacher=nullptr) : teacher(teacher) {}
};
int main()
{
// Create a teacher outside the scope of the Department
Teacher* teacher = new Teacher("Bob"); // create a teacher
{
Department dept(teacher);
} // dept goes out of scope here and is destroyed
// Teacher still exists here because dept did not delete teacher
std::cout << teacher->getName() << " still exists!";
delete teacher;
return 0;
}
In this case, teacher is created independently of dept, and then passed into dept’s constructor. When dept is destroyed, the teacher pointer is destroyed, but the teacher itself is not deleted, so it still exists until it is independently destroyed later in main().
Pick the right relationship for what you are modelling
Although it might seem a little silly in the above example that the Teacher’s don’t know what Department they’re working for, that may be totally fine in the context of a given program. When you’re determining what kind of relationship to implement, implement the simplest relationship that meets your needs, not the one that seems like it would fit best in a real-life context.
For example, if you’re writing a body shop simulator, you may want to implement a car and engine as an aggregation, so the engine can be removed and put on a shelf somewhere for later. However, if you’re writing a racing simulation, you may want to implement a car and an engine as a composition, since the engine will never exist outside of the car in that context.
Rule: Implement the simplest relationship type that meets the needs of your program, not what seems right in real-life.
Summary of composition and aggregation
Compositions:
- Typically use normal member variables
- Can use pointer values if the composition class automatically handles allocation/deallocation
- Responsible for creation/destruction of parts
Aggregations:
- Typically use pointer or reference members that point to or reference objects that lives outside the scope of the aggregate class
- Not responsible for creating/destroying parts
It is worth noting that the concepts of composition and aggregation are not mutually exclusive, and can be mixed freely within the same class. It is entirely possible to write a class that is responsible for the creation/destruction of some parts but not others. For example, our Department class could have a name and a Teacher. The name would probably be added to the Department by composition, and would be created and destroyed with the Department. On the other hand, the Teacher would be added to the department by aggregation, and created/destroyed independently.
While aggregations can be extremely useful, they are also potentially more dangerous. Because aggregations do not handle deallocation of their parts, that is left up to an external party to do so. If the external party no longer has a pointer or reference to the abandoned parts, or if it simply forgets to do the cleanup (assuming the class will handle that), then memory will be leaked.
For this reason, compositions should be preferred over aggregations.
References
http://upcoder.com/17/who-owns-who
http://harmful.cat-v.org/software/OO_programming/why_oo_sucks