Lesson 4 - Pointers
For a C++ program, the memory of a computer is like a succession of memory cells, each one byte in size, and each with a unique address. These single-byte memory cells are ordered in a way that allows data representations larger than one byte to occupy memory cells that have consecutive addresses.
This way, each cell can be easily located in the memory by means of its unique address. For example, the memory cell with the address 1776 always follows immediately after the cell with address 1775 and precedes the one with 1777, and is exactly one thousand cells after 776 and exactly one thousand cells before 2776.
When a variable is declared, the memory needed to store its value is assigned a specific location in memory (its memory address). Generally, C++ programs do not actively decide the exact memory addresses where its variables are stored. That task is left to the environment where the program is run - generally, an operating system that decides the particular memory locations on runtime. However, it may be useful for a program to be able to obtain the address of a variable during runtime in order to access data cells that are at a certain position relative to it.
Raw Pointers
Raw pointers represent direct address to a specific memory location. These were the only option in C, but C++ for a long time has come up with safer alternatives to using raw pointers. They have now been formally introduced into the STL as of C++11.
Address-of operator (&)
The address of a variable can be obtained by preceding the name of a variable with an ampersand sign (&), known as address-of operator. For example:
foo = &myvar;
This would assign the address of variable myvar to foo; by preceding the name of the variable myvar with the address-of operator (&), we are no longer assigning the content of the variable itself to foo, but its address.
The actual address of a variable in memory cannot be known before runtime, but let's assume, in order to help clarify some concepts, that myvar is placed during runtime in the memory address 1776.
In this case, consider the following code fragment:
myvar = 25;
foo = &myvar;
bar = myvar;
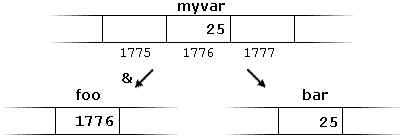
The variable that stores the address of another variable (like
foo in the previous example) is what in C++ is called a pointer. Pointers are a very powerful feature of the language that has many uses in lower level programming. Dereference operator (*)
As just seen, a variable which stores the address of another variable is called a pointer. Pointers are said to "point to" the variable whose address they store.
An interesting property of pointers is that they can be used to access the variable they point to directly. This is done by preceding the pointer name with the dereference operator (
*). The operator itself can be read as "value pointed to by".Therefore, following with the values of the previous example, the following statement:
baz = *foo;
baz equal to value pointed to by foo", and the statement would actually assign the value 25 to baz, since foo is 1776, and the value pointed to by 1776 (following the example above) would be 25.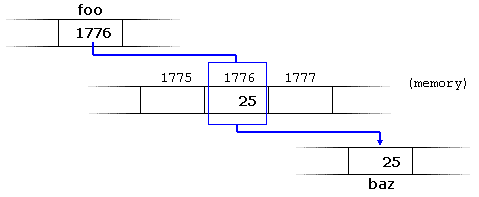
It is important to clearly differentiate that
foo refers to the value 1776, while *foo (with an asterisk * preceding the identifier) refers to the value stored at address 1776, which in this case is 25. Notice the difference of including or not including the dereference operator: baz = foo; // baz equal to foo (1776)
baz = *foo; // baz equal to value pointed to by foo (25)
&is the address-of operator, and can be read simply as "address of"*is the dereference operator, and can be read as "value pointed to by"
Thus, they have sort of opposite meanings: An address obtained with
& can be dereferenced with *. You may also infer that for as long as the address pointed to by foo remains unchanged, the following expression will also be true:*foo == myvar
Declaring pointers
Due to the ability of a pointer to directly refer to the value that it points to, a pointer has different properties when it points to a
char than when it points to an int or a float. Once dereferenced, the type needs to be known. And for that, the declaration of a pointer needs to include the data type the pointer is going to point to.The declaration of pointers follows this syntax:
type* name;
where type is the data type pointed to by the pointer. This type is not the type of the pointer itself, but the type of the data the pointer points to. For example:
int* number;
char* character;
double* decimals;
int, the second one to a char, and the last one to a double. Therefore, although these three example variables are all pointers, they actually have different types: int*, char*, and double* respectively, depending on the type they point to.Note that the asterisk (
*) used when declaring a pointer only means that it is a pointer (it is part of its type compound specifier), and should not be confused with the dereference operator seen a bit earlier, but which is also written with an asterisk (*). They are simply two different things represented with the same sign.Pointers and arrays
The concept of arrays is related to that of pointers. In fact, arrays work very much like pointers to their first elements, and, actually, an array can always be implicitly converted to the pointer of the proper type. For example, consider these two declarations:
int myarray [20];
int* mypointer;
The following assignment operation would be valid:
mypointer = myarray;
mypointer and myarray would be equivalent and would have very similar properties. The main difference being that mypointer can be assigned a different address, whereas myarray can never be assigned anything, and will always represent the same block of 20 elements of type int. Therefore, the following assignment would not be valid:Pointers and arrays support the same set of operations, with the same meaning for both. The main difference being that pointers can be assigned new addresses, while arrays cannot.
In the lesson about arrays, brackets ([]) were explained as specifying the index of an element of the array. In fact these brackets are a dereferencing operator known as offset operator. They dereference the variable they follow just as * does, but they also add the number between brackets to the address being dereferenced. For example:
a[5] = 0; // a [offset of 5] = 0
*(a+5) = 0; // pointed to by (a+5) = 0
These two expressions are equivalent and valid, not only if a is a pointer, but also if a is an array. Remember that if an array, its name can be used just like a pointer to its first element.
Pointer arithmetics
Arithmetical operations on pointers is a little different than on regular integer types. Only addition and subtraction operations are allowed; the others make no sense in the world of pointers. But both addition and subtraction have a slightly different behaviour with pointers, according to the size of the data type to which they point.
Types have different sizes (depending upon underlying hardware). For example:
char always has a size of 1 byte, short is generally larger than that, and int and long are even larger; the exact size of these being dependent on the system. For example, let's imagine that in a given system, char takes 1 byte, short takes 2 bytes, and int takes 4.Suppose now that we define three pointers in this compiler:
char* mychar;
short* myshort;
int* mylong;
and that we know that they point to the memory locations 1000, 2000, and 3000, respectively.
Therefore, if we write:
++mychar;
++myshort;
++mylong;
mychar, as one would expect, would contain the value 1001. But not so obviously, myshort would contain the value 2002, and mylong would contain 3004, even though they have each been incremented only once. The reason is that, when adding one to a pointer, the pointer is made to point to the following element of the same type, and, therefore, the size in bytes of the type it points to is added to the pointer.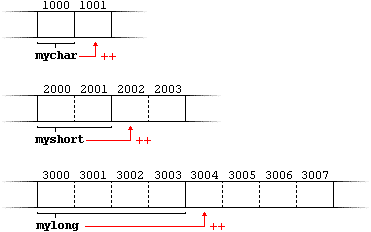
Pointers and const
Pointers can be used to access a variable by its address, and this access may include modifying the value pointed. But it is also possible to declare pointers that can access the pointed value to read it, but not to modify it. For this, it is enough to qualify the type pointed to by the pointer as
const. For example:p points to a variable, but points to it in a const-qualified manner, meaning that it can read the value pointed, but it cannot modify it. Note also, that the expression &y is of type int*, but this is assigned to a pointer of type const int*. This is allowed: a pointer to non-const can be implicitly converted to a pointer to const. But not the other way around! As a safety feature, pointers to const are not implicitly convertible to pointers to non-const.One of the use cases of pointers to const elements is as function parameters: a function that takes a pointer to non-
const as parameter can modify the value passed as argument, while a function that takes a pointer to const as parameter cannot.Pointers can also be themselves
const. And this is specified by appending const to the pointed type (after the asterisk):int x;
int* p1 = &x; // non-const pointer to non-const int
const int* p2 = &x; // non-const pointer to const int
int* const p3 = &x; // const pointer to non-const int
const int* const p4 = &x; // const pointer to const int
The syntax with const and pointers is definitely tricky, and recognising the cases that best suit each use tends to require some experience. In any case, it is important to get const’ness with pointers (and references) right sooner rather than later, but you should not worry too much about grasping everything if this is the first time you are exposed to the mix of const and pointers.
To add a little bit more confusion to the syntax of const with pointers, the const qualifier can either precede or follow the pointed type, with the exact same meaning:
const int* p2a = &x; // non-const pointer to const int
int const* p2b = &x; // also non-const pointer to const int
Pointers and string literals
String literals are arrays containing
null-terminated character sequences. But they can also be accessed directly. String literals are arrays of the proper array type to contain all its characters plus the terminating null-character, with each of the elements being of type const char (as literals, they can never be modified). For example:const char* foo = "hello";
foo. If we imagine that "hello" is stored at the memory locations that start at address 1702, we can represent the previous declaration as: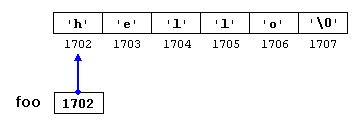
The pointer
foo points to a sequence of characters. And because pointers and arrays behave essentially in the same way in expressions, foo can be used to access the characters in the same way arrays of null-terminated character sequences are. For example:*(foo+4)
foo[4]
Pointers to pointers
C/C++ allows the use of pointers that point to pointers, that these, in its turn, point to data (or even to other pointers). The syntax simply requires an asterisk (
*) for each level of indirection in the declaration of the pointer:char a;
char* b;
char** c;
a = 'z';
b = &a;
c = &b;
7230, 8092, and 10502, could be represented as: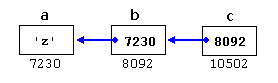
With the value of each variable represented inside it’s corresponding cell, and their respective addresses in memory represented by the value under them.
The new thing in this example is variable
c, which is a pointer to a pointer, and can be used in three different levels of indirection, each one of them would correspond to a different value:cis of typechar**and a value of8092*cis of typechar*and a value of7230**cis of type char and a value of'z'
Pointers to pointers are usually used as function parameters, when the intention is for the function to reassign the pointer pointee to another value. Remember that pointers are passed by value, hence a regular pointer that is reassigned in the function implementation would only affect the local copy within the function scope, and leave unaffected the original pointer passed as argument in the function invocation.
void pointers
The
void type of pointer is a special type of pointer. In C++, void represents the absence of type. Therefore, void pointers are pointers that point to a value that has no type (and thus also an undetermined length and undetermined dereferencing properties).This gives
void pointers a great flexibility, by being able to point to any data type, from an integer value or a float to a string of characters. In exchange, they have a great limitation: the data pointed to by them cannot be directly dereferenced (which is logical, since we have no type to dereference to), and for that reason, any address in a void pointer needs to be transformed into some other pointer type that points to a concrete data type before being dereferenced.One of its possible uses may be to pass generic parameters to a function.
#include <iostream>
void increase( void* data, int psize )
{
if ( psize == sizeof(char) ) { char* pchar; pchar=(char*)data; ++(*pchar); }
else if (psize == sizeof(int) ) { int* pint; pint=(int*)data; ++(*pint); }
}
int main ()
{
char a = 'x';
int b = 1602;
increase (&a,sizeof(a));
increase (&b,sizeof(b));
std::cout << a << ", " << b << std::endl;
return 0;
}
sizeof is an operator integrated in the C++ language that returns the size in bytes of its argument. For non-dynamic data types, this value is a constant. Therefore, for example, sizeof(char) is 1, because char has always a size of one byte.Invalid pointers and null pointers
In principle, pointers are meant to point to valid addresses, such as the address of a variable or the address of an element in an array. But pointers can actually point to any address, including addresses that do not refer to any valid element. Typical examples of this are uninitialised pointers and pointers to nonexistent elements of an array:
int* p; // uninitialised pointer (local variable)
int myarray[10];
int* q = myarray+20; // element out of bounds
p nor q point to addresses known to contain a value, but none of the above statements causes an error. In C++, pointers are allowed to take any address value, no matter whether there actually is something at that address or not. What can cause an error is to dereference such a pointer (i.e., actually accessing the value they point to). Accessing such a pointer causes undefined behaviour, ranging from an error during runtime to accessing some random value.But, sometimes, a pointer really needs to explicitly point to nowhere, and not just an invalid address. For such cases, there is a special value that any pointer type can take: the
null pointer value. This value can be expressed in C++ in two ways: either with an integer value of zero, or with the nullptr keyword:int* p = 0;
int* q = nullptr;
Here, both p and q are null pointers, meaning that they explicitly point to nowhere, and they both actually compare equal: all null pointers compare equal to other null pointers. It is also quite usual to see the defined constant NULL be used in older code to refer to the null pointer value:
int* r = NULL;
NULL is defined in several headers of the standard library, and is defined as an alias of some null pointer constant value (such as 0 or nullptr).
null pointers with void pointers! A null pointer is a value that any pointer can take to represent that it is pointing to "nowhere", while a void pointer is a type of pointer that can point to somewhere without a specific type. One refers to the value stored in the pointer, and the other to the type of data it points to.Pointers to functions
C++ allows operations with pointers to functions. The typical use of this is for passing a function as an argument to another function. Pointers to functions are declared with the same syntax as a regular function declaration, except that the name of the function is enclosed between parentheses
() and an asterisk (*) is inserted before the name:#include <iostream>
int addition( int a, int b ) { return a+b; }
int subtraction( int a, int b ) { return a-b; }
int operation( int x, int y, int (*functocall)( int, int ) )
{
int g;
g = (*functocall)( x, y );
return g;
}
int main()
{
int m, n;
int (*minus)( int, int ) = subtraction;
m = operation( 7, 5, addition );
n = operation( 20, m, minus );
std::cout << n << std::endl;
return 0;
}
In the example above, minus is a pointer to a function that has two parameters of type int. It is directly initialised to point to the function subtraction:
int (* minus)(int,int) = subtraction;
Pointers to classes
Objects can also be pointed to by pointers: Once declared, a class becomes a valid type, so it can be used as the type pointed to by a pointer. For example:
Rectangle* prect;
is a pointer to an object of class Rectangle.
The members of an object can be accessed directly from a pointer by using the arrow operator (->).
c++
prect->length;
prect->area();
Dynamic Memory
There are cases where the memory needs of a program can only be determined during runtime. For example, when the memory needed depends on user input. In these cases, programs need to dynamically allocate memory, for which the C++ language provide the operators
new and delete.Operators new and new[]
Dynamic memory is allocated using operator
new. new is followed by a data type specifier and, if a sequence of more than one element is required, the number of these within brackets []. It returns a pointer to the beginning of the new block of memory allocated. Its syntax is:pointer = new type
pointer = new type [number_of_elements]
The first expression is used to allocate memory to contain one single element of type type. The second one is used to allocate a block (an array) of elements of type type, where number_of_elements is an integer value representing the amount of these. For example:
int* foo = new int [5];
int and returns a pointer to the first element of the sequence, which is assigned to foo (a pointer). Therefore, foo now points to a valid block of memory with space for five elements of type int.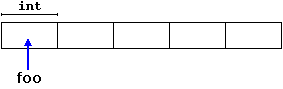
Here,
foo is a pointer, and thus, the first element pointed to by foo can be accessed either with the expression foo[0] or the expression *foo (both are equivalent). The second element can be accessed either with foo[1] or *(foo+1), and so on...There is a substantial difference between declaring a normal array and allocating dynamic memory for a block of memory using
new. The most important difference is that the size of a regular array needs to be a constant expression, and thus its size has to be determined at the moment of designing the program, before it is run, whereas the dynamic memory allocation performed by new allows to assign memory during runtime using any variable value as size.The dynamic memory requested by our program is allocated by the system from the memory heap. However, computer memory is a limited resource, and it can be exhausted. Therefore, there are no guarantees that all requests to allocate memory using operator
new are going to be granted by the system. C++ provides two standard mechanisms to check if the allocation was successful:
One is by handling exceptions. Using this method, an exception of type
std::bad_alloc is thrown when the allocation fails. If this exception is thrown and it is not handled by a specific handler, the program execution is terminated.This exception method is the method used by default by
new, and is the one used in a declaration like:foo = new int [5]; // if allocation fails, an exception is thrown
The other method is known as nothrow, when a memory allocation fails, instead of throwing a bad_alloc exception or terminating the program, the pointer returned by new is a null pointer, and the program continues its execution normally.
This method can be specified by using a special object called nothrow, declared in header <new>, as argument for new:
foo = new (nothrow) int [5];
In this case, if the allocation of this block of memory fails, the failure can be detected by checking if foo is a null pointer:
int* foo = new (nothrow) int [5];
if (foo == nullptr) { // error assigning memory. Take measures. }
nothrow method is likely to produce less efficient code than exceptions, since it implies explicitly checking the pointer value returned after each and every allocation. Therefore, the exception mechanism is generally preferred, at least for critical allocations.Operators delete and delete[]
In most cases, memory allocated dynamically is only needed during specific periods of time within a program; once it is no longer needed, it can be freed so that the memory becomes available again for other requests of dynamic memory. This is the purpose of operator
delete, whose syntax is:delete pointer;
delete[] pointer;
new, and the second one releases the memory allocated for arrays of elements using new and a size in brackets ([]).The value passed as argument to
delete shall be either a pointer to a memory block previously allocated with new, or a null pointer (in the case of a null pointer, delete produces no effect).Usage Patterns
Dynamically allocated memory needs to be handled with a lot of care to avoid program (or system in worst case) crashes and memory leaks. Memory leaks are caused when calls to
new are not followed up with corresponding calls to delete. Code analysers are available that will identify memory leaks in your program.There are standard patterns that are expected to be followed when working with raw pointers (specifically when dealing with dynamic memory).
- Check to ensure that a pointer is valid (not
nullptr) before attempting to dereference it. This helps reduce errors with using dangling pointers in one section of code (say a class instance variable), that may have been caused by memory being freed in another part of code. - Set pointers to
nullptras soon as they have been deleted. This helps reduce issues associated with using dangling pointers (pointers to memory that has already been freed). - Any function that returns a pointer to dynamically allocated memory must document the fact that the caller is responsible for freeing up the memory associated with that pointer. This assumes that the caller has read the documentation. It is often better to write a function that takes as a parameter pre-allocated pointer, and modifies as appropriate.
- Keep
new/deleteas close to each other as possible. It makes it much easier to account fornew/deletecombinations if they are close to each other (usually in the same function/code block). - Classes that use dynamic memory allocation (usually in constructor), should free the memory in its destructor.
Disadvantages
Raw pointers are extremely powerful, but used incorrectly can cause significant damage to the running program, or in the worst case to the entire system on which the program is running.
- The concept of ownership (which piece of code is responsible for creating and freeing memory) needs to be rigorously enforced.
- Pointer arithmetic may cause code to access memory totally outside the program scope leading to corruption of the entire system.
- Multiple locations in the code base may need access to the same dynamically allocated memory. It becomes very hard to keep track of all usages and free the memory only after all uses for that memory are over. This can lead to either a dangling pointer issue, or double delete (attempting to free already freed memory).
- When exceptions are thrown, previously allocated memory may not have been freed (use of RAII alleviates this).
Smart Pointers
Smart pointers are abstractions built on top of raw pointer with the view of reducing the issues that dealing directly with pointer types introduce. Smart pointers take over ownership of the raw pointer, leading to a unified location for managing the memory. Smart pointers usually do not support pointer arithmetic.
Ownership is a bookkeeping technique for managing dynamically allocated memory (and other resources). The owner of a dynamically allocated object is an object or function that is responsible for ensuring that it is deleted when no longer needed. Ownership can sometimes be shared, in which case the last owner is typically responsible for deleting it. Even when ownership is not shared, it can be transferred from one piece of code to another.
Various forms of smart pointers have been around since the 1990’s, usually as part of third-party libraries, or add on packages from standard compiler vendors. C++11 added a few types of smart pointers to the STL.
Smart pointers are classes that act like pointers, e.g. by overloading the
* and -> operators. Some smart pointer types can be used to automate ownership bookkeeping, to ensure these responsibilities are met. std::unique_ptr is a smart pointer type introduced in C++11, which expresses exclusive ownership of a dynamically allocated object; the object is deleted when the std::unique_ptr goes out of scope. It cannot be copied, but can be moved to represent ownership transfer. std::shared_ptr is a smart pointer type that expresses shared ownership of a dynamically allocated object. std::shared_ptrs can be copied; ownership of the object is shared among all copies, and the object is deleted when the last std::shared_ptr is destroyed.Benefits
- It's virtually impossible to manage dynamically allocated memory without some sort of ownership logic.
- Transferring ownership of an object can be cheaper than copying it (if copying it is even possible).
- Transferring ownership can be simpler than 'borrowing' a pointer or reference, because it reduces the need to coordinate the lifetime of the object between the two users.
- Smart pointers can improve readability by making ownership logic explicit, self-documenting, and unambiguous.
- Smart pointers can eliminate manual ownership bookkeeping, simplifying the code and ruling out large classes of errors.
- For const objects, shared ownership can be a simple and efficient alternative to deep copying.
- Implements RAII (resource allocation is initialisation) for dynamically allocated memory. Makes sure that no leaks result if an exception is thrown.
Disadvantages
- Shared ownership requires explicit bookkeeping at run-time, which can be costly.
- In some cases (e.g. cyclic references), objects with shared ownership may never be deleted.
- Smart pointers are not perfect substitutes for plain pointers.
std::unique_ptr
Manages the storage of a pointer, providing a limited garbage-collection facility, with little to no overhead over built-in pointers (depending on the deleter used).
These objects have the ability of taking ownership of a pointer: once they take ownership they manage the pointed object by becoming responsible for its deletion at some point.
unique_ptr objects automatically delete the object they manage (using a deleter) as soon as they themselves are destroyed, or as soon as their value changes either by an assignment operation or by an explicit call to unique_ptr::reset.unique_ptr objects own their pointer uniquely: no other facility shall take care of deleting the object, and thus no other managed pointer should point to its managed object, since as soon as they have to, unique_ptr objects delete their managed object without taking into account whether other pointers still point to the same object or not, and thus leaving any other pointers that point there as pointing to an invalid location. std::unique_ptr<int> iptr{ new int{ 1 } };
std::unique_ptr<int[]> iaptr{ new int[5]{ 1, 2, 3, 4, 5 } };
unique_ptr object has two components:- stored pointer: the pointer to the object it manages. This is set on construction, can be altered by an assignment operation or by calling member
reset, and can be individually accessed for reading using membersgetorrelease. - stored deleter: a callable object that takes an argument of the same type as the stored pointer and is called to delete the managed object. It is set on construction, can be altered by an assignment operation, and can be individually accessed using member
get_deleter.
unique_ptr objects replicate a limited pointer functionality by providing access to its managed object through operators * and -> (for individual objects), or operator [] (for array objects). For safety reasons, they do not support pointer arithmetics, and only support move assignment (disabling copy assignments).std::shared_ptr
Manages the storage of a pointer, providing a limited garbage-collection facility, possibly sharing that management with other objects.
Objects of
shared_ptr types have the ability of taking ownership of a pointer and share that ownership: once they take ownership, the group of owners of a pointer become responsible for its deletion when the last one of them releases that ownership.shared_ptr objects release ownership on the object they co-own as soon as they themselves are destroyed, or as soon as their value changes either by an assignment operation or by an explicit call to shared_ptr::reset. Once all shared_ptr objects that share ownership over a pointer have released this ownership, the managed object is deleted (normally by calling ::delete, but a different deleter may be specified on construction).shared_ptr objects can only share ownership by copying their value: If two shared_ptr are constructed (or made) from the same (non-shared_ptr) pointer, they will both be owning the pointer without sharing it, causing potential access problems when one of them releases it (deleting its managed object) and leaving the other pointing to an invalid location.std::weak_ptr
Weak pointers just observe the managed object; they do not keep it alive or affect its lifetime. Unlike
shared_ptrs, when the last weak_ptr goes out of scope or disappears, the pointed-to object can still exist because the weak_ptrs do not affect the lifetime of the object - they have no ownership rights. But the weak_ptr can be used to determine whether the object exists, and to provide a shared_ptr that can be used to refer to it. The definition of weak_ptr is designed to make it relatively foolproof, as a result there is very little you can do directly with a weak_ptr. For example, you can't dereference it; neither operator* nor operator-> is defined for a weak_ptr. You can't access the pointer to the object with it - there is no get() function. There is a comparison function defined so that you can store weak_ptrs in an ordered container; but that's all.Weak pointers are used to prevent cyclical object graphs (objects that reference each other). Cyclical object graphs that use
shared_ptrs to refer to each other may lead to none of the objects getting deleted as their ref-count would never become zero. When designing bi-directional relationships, the relation in one direction will be expressed as a weak_ptr helping to break the cycle.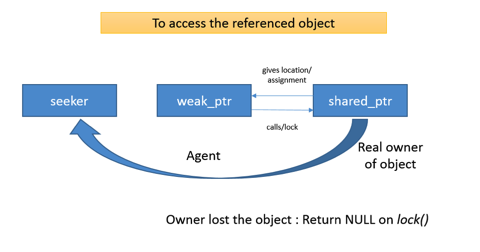
#include <iostream>
#include <memory>
int main ()
{
std::shared_ptr<int> sp1,sp2;
std::weak_ptr<int> wp;
// sharing group:
// --------------
sp1 = std::make_shared<int>( 20 ); // sp1
wp = sp1; // sp1, wp
sp2 = wp.lock(); // sp1, wp, sp2
sp1.reset(); // wp, sp2
sp1 = wp.lock(); // sp1, wp, sp2
std::cout << "*sp1: " << *sp1 << '\n';
std::cout << "*sp2: " << *sp2 << '\n';
return 0;
}
References
References are similar to pointers in a lot of ways. A lot of compilers will use a const pointer to act as a reference. There are however a few major (other than syntactical differences) differences between references and pointers.
- References must refer to a valid memory address. In other words, there is no equivalent of null pointers (
nullptror memory address 0). - References may not be reassigned to the memory address of another object. In this regard they behave similar to constant pointers.
- There is no equivalent of pointer arithmetic for references.
These two key differences govern the choice of when to use references vs pointers. References are used in situations where there is always a guarantee that a particular value exists. In cases where you cannot guarantee a particular value exists, pointers are generally used (or throwing an exception).