Lesson 3 - Search and Sort Algorithms
In this session we will cover a couple of very simple and popular search and sort algorithms. We will cover some implementation details as well as unit tests for our implementation in Lab 3.
Search Algorithms
We will discuss implementation details of the following algorithms:
- Linear Search - The simplest and most basic search algorithm. Uses a brute force approach of iterating over elements of a dataset in sequence until the value being searched is found.
- Binary Search - A far more efficient search algorithm. This algorithm however depends on the input dataset being sorted.
Linear Search
A linear search is the most basic of search algorithm you can have. A linear search sequentially moves through your collection (or data structure) looking for a matching value.
The worst case performance scenario for a linear search is that it needs to loop through the entire dataset; either because the item is the last one, or because the item is not found. In other words, if you have N items in your dataset, the worst case scenario to find an item is N iterations. This is known as O(N) using the Big-O Notation. The speed of search grows linearly with the number of items within your collection.
Linear searches do not require the collection to be sorted. Plenty of scripting languages libraries that provide a find function usually use linear search. These libraries tend to be used with small datasets, making a linear search an acceptable choice.
In some cases, you will know ahead of time that some items will be disproportionally searched for. In such situations, frequently requested items can be kept at the start of the collection. This can result in exceptional performance, regardless of size, for these frequently requested items.
Binary Search
Binary search relies on a divide and conquer strategy to find a value within an already-sorted collection. The algorithm is deceptively simple, and similar to hot-cold games.
One person asks another person to think of a number between 1 and 100 (say 68). They then try to guess the number. Every guess the person takes, the other will say higher or lower. The most efficient way to discover the number is to first guess 50. Higher - 75. Lower - 62. Higher - 68. Yes!
Every iteration eliminates half of the remaining possibilities. This makes binary searches very efficient - even for large datasets.
Binary search requires a sorted dataset. This means the collection must either be sorted before searching or be stored in a data structure that automatically stores the data pre-sorted.
Binary searching is frequently used thanks to its performance characteristics over large datasets. Binary search does not make sense when the dataset is frequently updated (relative to searches), since re-sorting will be required.
Sort Algorithms
We will discuss implementation details of the following algorithms:
- Bubble Sort - A very simple algorithm that works by comparing the two left most items in a dataset and swapping them if the second value is less than the first value. This process is repeated over and over until the full dataset is sorted.
- Selection Sort - Another simple algorithm that works by iterating over the dataset and identifying the smallest value, which is swapped into the first position in the dataset. Subsequent iterations starting after the previously set minimum values cover the entire dataset resulting in a properly sorted dataset.
Bubble Sort
Bubble sort is the most basic way to sort a dataset. It works by sequentially going through a dataset and comparing two values at a time, swapping them if necessary. It then repeats the process until no swaps are required.
Bubble sort requires a lot of steps in order to sort even a small dataset. There are two interesting things to know about bubble sorts:
- Large values are always sorted first. The algorithm implementation can stop repeatedly iterating over already sorted values.
- It only takes one iteration to detect that a collection is already sorted, this is not a unique property of bubble sorts.
There are no real practical applications for bubble sort due to its inefficiency (O(n2)). This algorithm is generally used in Computer Science courses primarily for historical reason as well as to exercise implementing an algorithm in a programming language.
Selection Sort
Selection sort is another very simple sorting algorithm. This sorting algorithm is an in-place comparison-based algorithm in which the dataset is divided into two parts, the sorted part at the left end and the unsorted part at the right end. Initially, the sorted part is empty and the unsorted part is the entire dataset. Note that you can keep the sorted part on the left, or the right, it just depends upon whether the algorithm looks for the minimum or maximum value.
The smallest item is selected from the unsorted dataset and swapped with the leftmost item, and that item becomes a part of the sorted dataset. This process continues moving unsorted dataset boundary by one item to the right.
Selection sort almost always outperforms bubble sort, however is still a very inefficient sorting algorithm (O(n2)).
Algorithm Efficiency
In computer science, algorithmic efficiency is expressed in terms of the properties of an algorithm which relate to the amount of computational resources used by the algorithm. Analysis of algorithms is the determination of the amount of resources (such as time and storage) necessary to execute them. Most algorithms are designed to work with inputs of arbitrary length. Usually, the efficiency or running time of an algorithm is stated as a function relating the input length to the number of steps (time complexity) or storage locations (space complexity). Algorithmic efficiency can be thought of as analogous to engineering productivity for a repeating or continuous process.
For maximum efficiency we wish to minimise resource usage. However, the various resources (e.g. time, space) cannot be compared directly, so which of two algorithms is considered to be more efficient often depends on which measure of efficiency is considered the most important, e.g. the requirement for high speed, minimum memory usage or some other measure of performance.
Big O Notation
Big O notation is a mathematical notation that describes the limiting behaviour of a function when the argument tends towards a particular value or infinity. It is a member of a family of notations invented by Paul Bachmann, Edmund Landau, and others, collectively called Bachmann–Landau notation or asymptotic notation.
Big O notation is used to classify algorithms by how they respond to changes in input size, such as how the processing time of an algorithm changes as the problem size becomes extremely large.
In typical usage, the formal definition of O notation is not used directly; rather, the O notation for a function f is derived by the following simplification rules:
- If f(x) is a sum of several terms, if there is one with largest growth rate, it can be kept, and all others omitted.
- If f(x) is a product of several factors, any constants (terms in the product that do not depend on x) can be omitted.
For example, let f(x) = 6x4 − 2x3 + 5, and suppose we wish to simplify this function, using O notation, to describe its growth rate as x approaches infinity. This function is the sum of three terms: 6x4, −2x3, and 5. Of these three terms, the one with the highest growth rate is the one with the largest exponent as a function of x, namely 6x4. Now one may apply the second rule: 6x4 is a product of 6 and x4 in which the first factor does not depend on x. Omitting this factor results in the simplified form x4. Thus, we say that f(x) is a "big-oh" of (x4). Mathematically, we can write f(x) = O(x4).
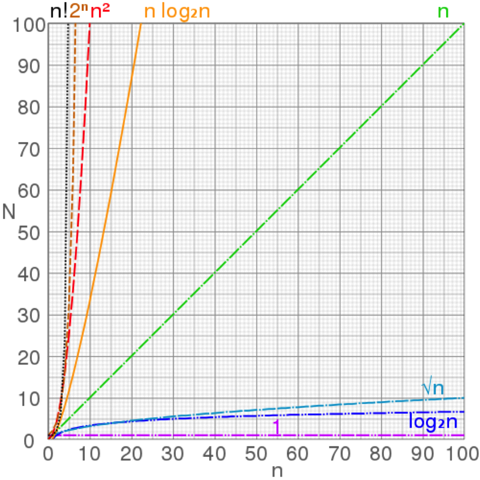
Graphs of number of operations, N vs input size, n for common complexities
References
http://www.bfilipek.com/2014/12/top-5-beautiful-c-std-algorithms.html
http://bigocheatsheet.com/